
特殊的栈溢出-整数溢出
整数溢出介绍
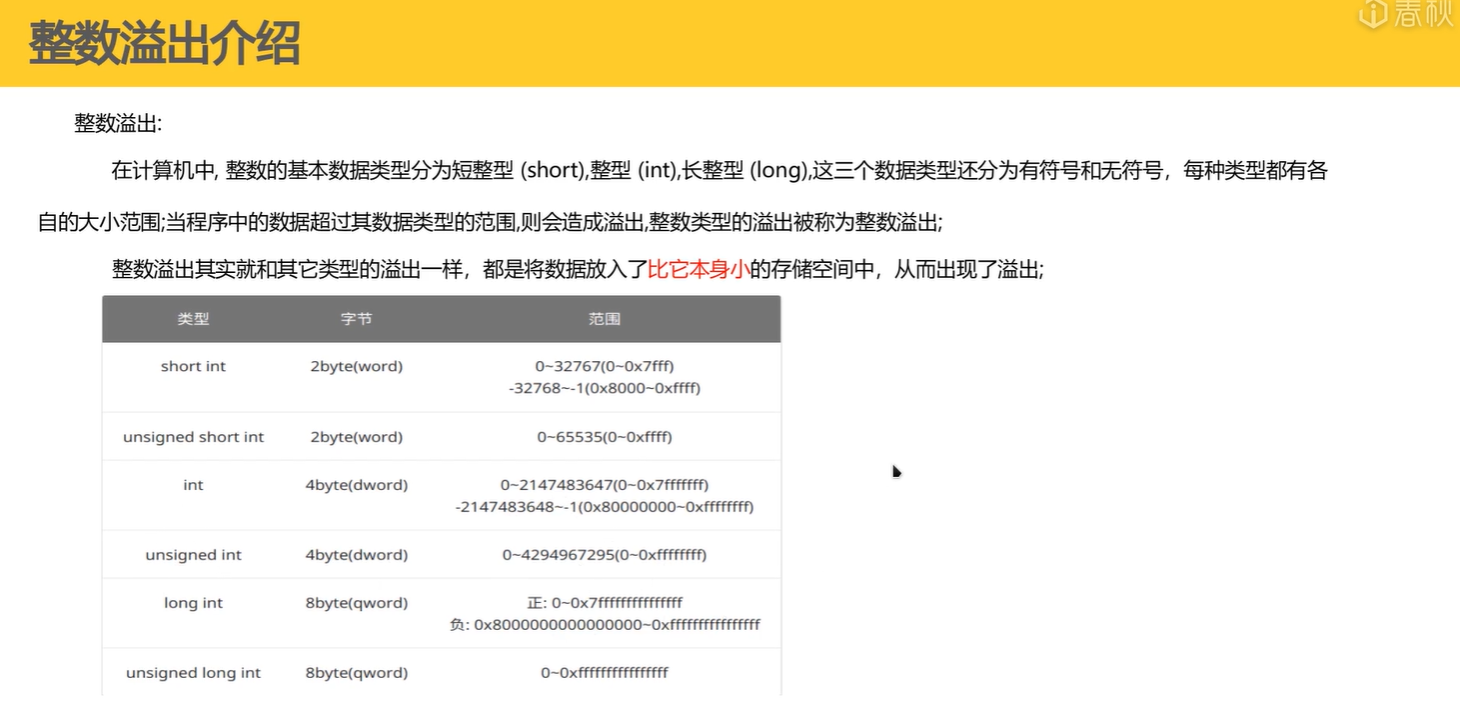
上界溢出(加法溢出add)
有符号上界溢出

有符号整数的补码存储规则32767+1=-32768
—— 计算机中所有有符号整数都用 “补码” 表示,这是溢出后数值回绕的根本原因。
1 | 1)先明确 short int 的基础属性 |
一句话总结
有符号 short int 的存储位数(16 位)和补码规则,决定了:
- 最大正数是 0x7FFF(32767),再 + 1 就会进位到符号位,变成 0x8000;
- 0x8000 按补码解读是 - 32768(有符号最小数);
- 本质是 “存储位数不够导致溢出,补码规则让溢出结果回绕到最小值”。
这也是所有有符号整数溢出的共性逻辑(比如 32 位 int 的 2147483647+1=-2147483648,原理完全一致,只是位数从 16 位变成 32 位)。
无符号上界溢出
1. 无符号short int的溢出示例
- 类型属性:
unsigned short int(2 字节)的取值范围是0(十六进制655350x00000xffff); - 溢出现象:当变量
b=0xffff(即 65535)时,执行b = b + 1,结果会溢出为0x0000(即 0)。
2. 底层汇编逻辑的差异
- 无符号运算的汇编指令:直接对内存中的 2 字节数据操作(
add word ptr [ebp - 0xa], 1),因0xffff + 1 = 0x10000,而 2 字节仅保留低 16 位,最终结果为0x0000; - 与有符号运算的共性:有符号
short int运算时,寄存器(eax)会得到0x10000,但仅将低 2 字节(ax=0x0000)写回内存,因此存储结果与无符号一致。
3. 数值层面的逻辑差异
| 类型 | 0xffff 的数值含义 | 0xffff + 1 的结果 | 结果的合理性 |
|---|---|---|---|
有符号short int |
-1 | 0 | 符合数学逻辑(-1+1=0) |
无符号short int |
65535 | 0 | 不符合数学逻辑(65535+1≠0) |
4. 核心结论
无符号整数的溢出本质是模运算结果(以 “类型最大值 + 1” 为模),而有符号整数的溢出则是补码规则下的数值回绕,二者因 “数值含义的定义不同”,导致同一存储结果的逻辑合理性存在差异。
下界溢出(减法溢出sub)

整数溢出的类型
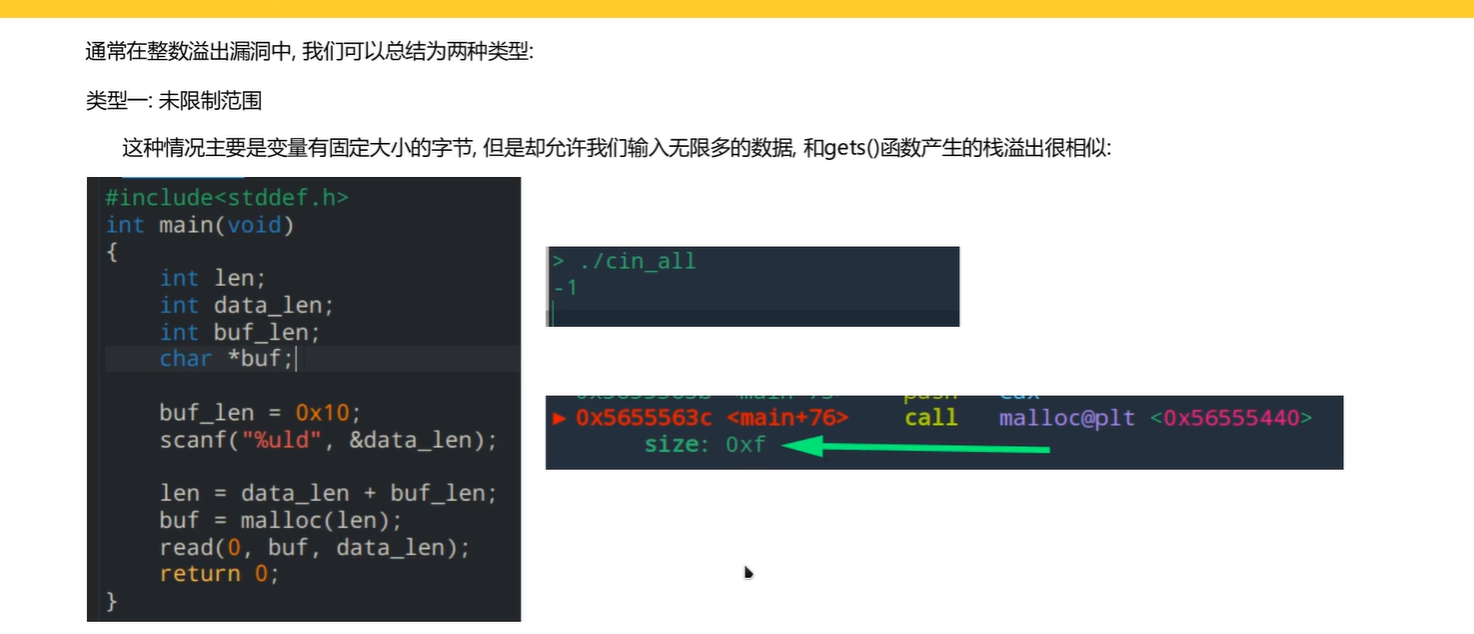
malloc申请大小的空间为0xf,将data_len读入到buf中会造成溢出
read(0,buf,data_len)
文件描述符(fd):0 是标准输入(stdin)的固定描述符(键盘 / 管道输入);
buf:内存缓冲区指针:指向一段连续内存(如数组、malloc 分配的空间),用于存储读取到的数据
data_len:期望读取的字节数:要求系统最多读取 data_len 个字节到 buf 中
通过IDA分析
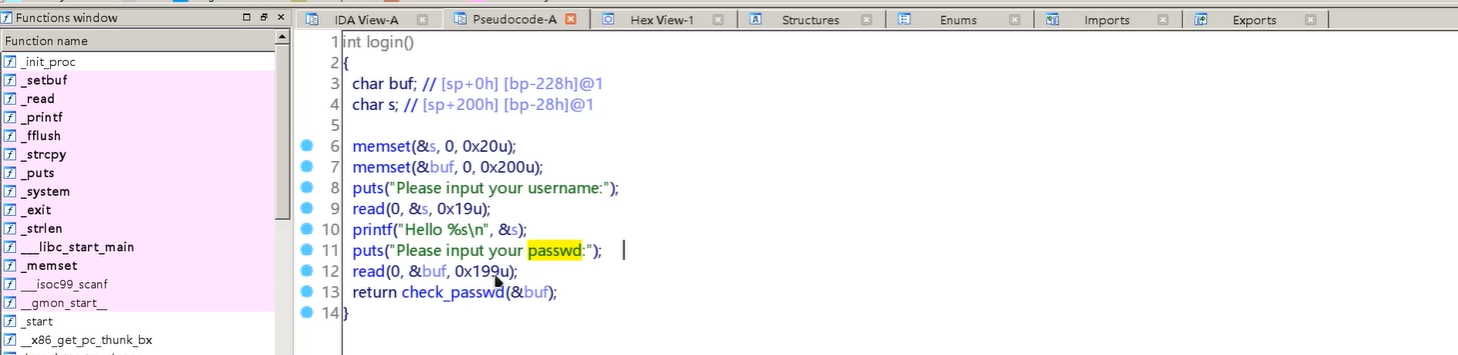
可以分析到buf至少是228个字节大于0x199u应该是不会有溢出的
例题//整数溢出
1)[BJDCTF 2020]babystack

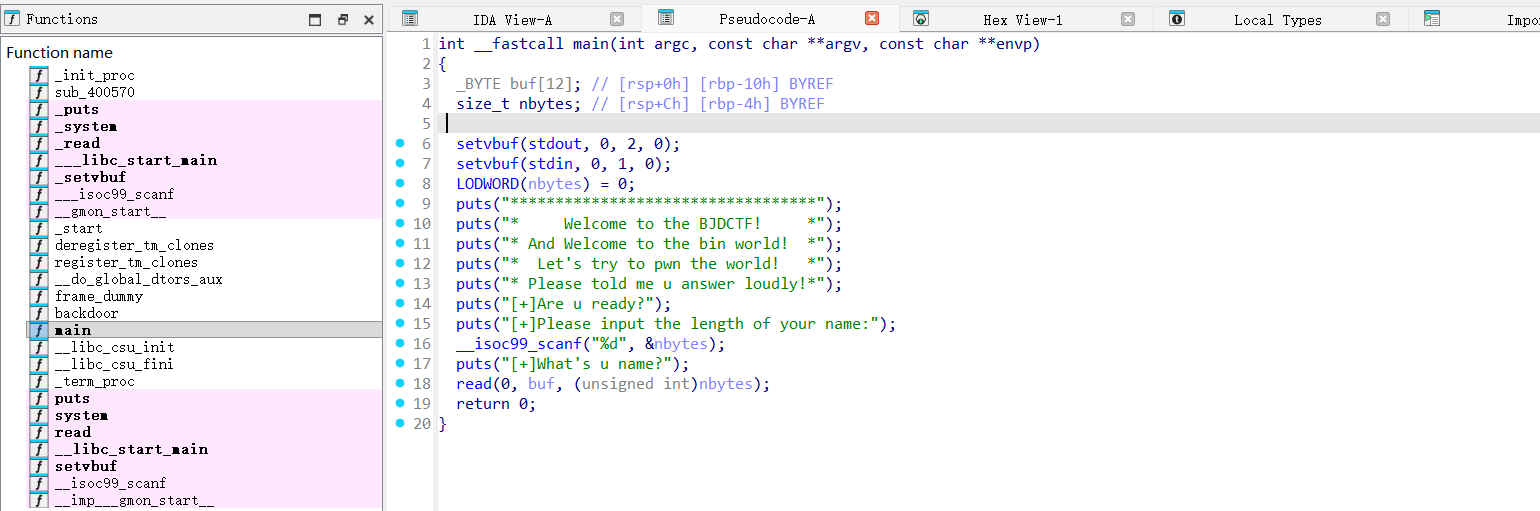
setvbuf(stdout, 0, 2, 0)
的核心是将标准输出设为无缓冲模式,在溢出调试、漏洞利用中是关键操作 —— 解决输出缓冲导致的信息丢失,确保调试 / 利用过程中能即时看到程序输出,精准分析溢出行为。
__isoc99_scanf("%d", &nbytes);:让用户输入下次输入时接受的数据的长度。read(0, &buf, (unsigned int)nbytes);:变量nbytes用户可控,存在栈溢出。
LODWORD(nbytes) = 0; (HIDWORD是高三十二位)
→ 把 nbytes 的低 32 位内存区域直接赋值为 0,分两种场景:
nbytes****类型 |
执行效果 | 内存示例(十六进制) |
|---|---|---|
| 32 位(DWORD) | 整个变量被置为 0(等价于nbytes = 0;) |
原0x12345678→ 置 0 后 0x00000000 |
| 64 位(DWORD64) | 低 32 位清 0,高 32 位保持不变 | 原0x11223344 55667788→ 置 0 后 0x11223344 |
| 操作 | 溢出后 nbytes(64 位) | 低 32 位值 | 32 位视角下的 read 长度 | 结果 |
|---|---|---|---|---|
| LODWORD(nbytes)=0; | 0x1000FFFF | 0 | 0 | 无操作,规避溢出 |
| 未清零低 32 位 | 0x1000FFFF | 0xFFFF | 65535 | 缓冲区溢出(风险) |
“截断” 的本质是:64 位nbytes本是完整的超大值,但LODWORD(nbytes)=0 强行把低 32 位 “砍断并清零”,相当于只保留高 32 位、丢弃低 32 位的有效数值;而 32 位程序只能识别低 32 位,因此最终操作长度被 “截断为 0”,从根源上避免了溢出后的超大长度导致的内存越界。
1 |
|
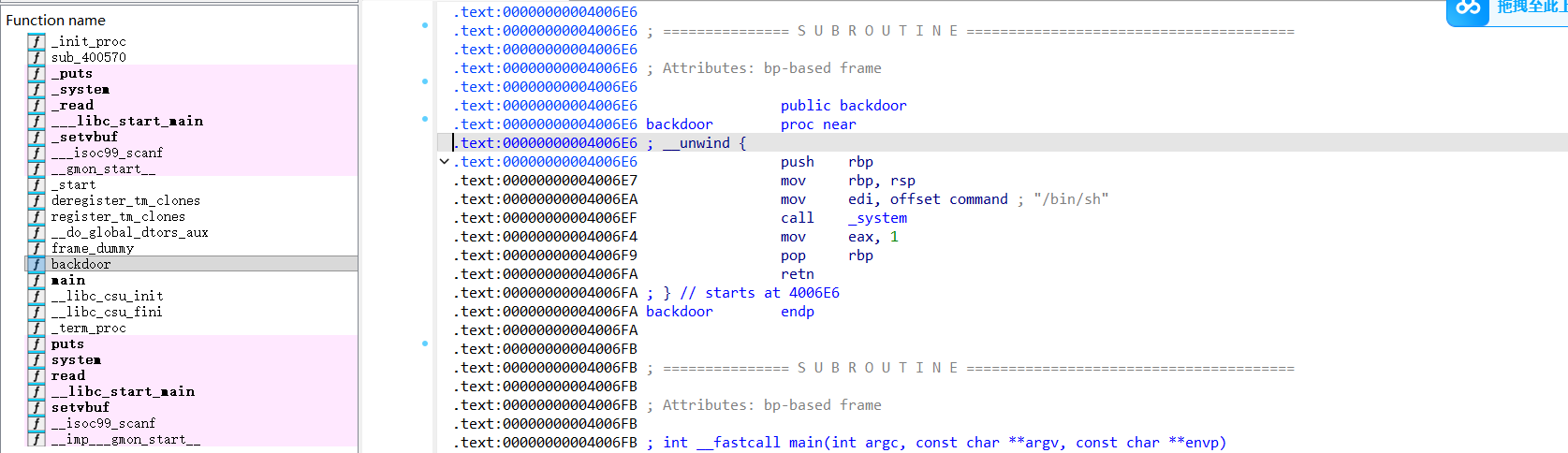
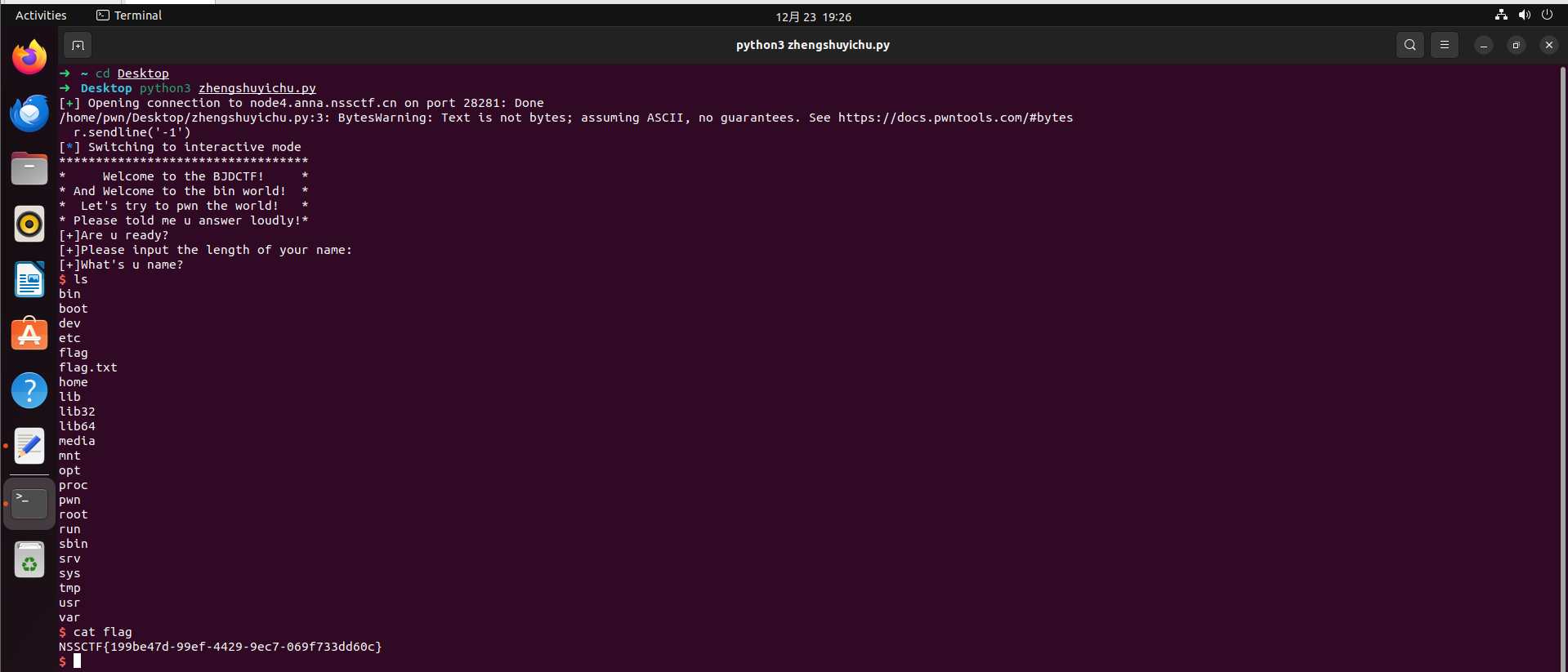
简单说一下题:通过IDA分析断定,输入长度取一个比较大的值,为后续溢出做准备,寻找覆盖当前栈和rbp的字节数以及后门函数构造payload就可以获取shell去拿flag。
exp 1)
1 | #导入pwntools模块: |
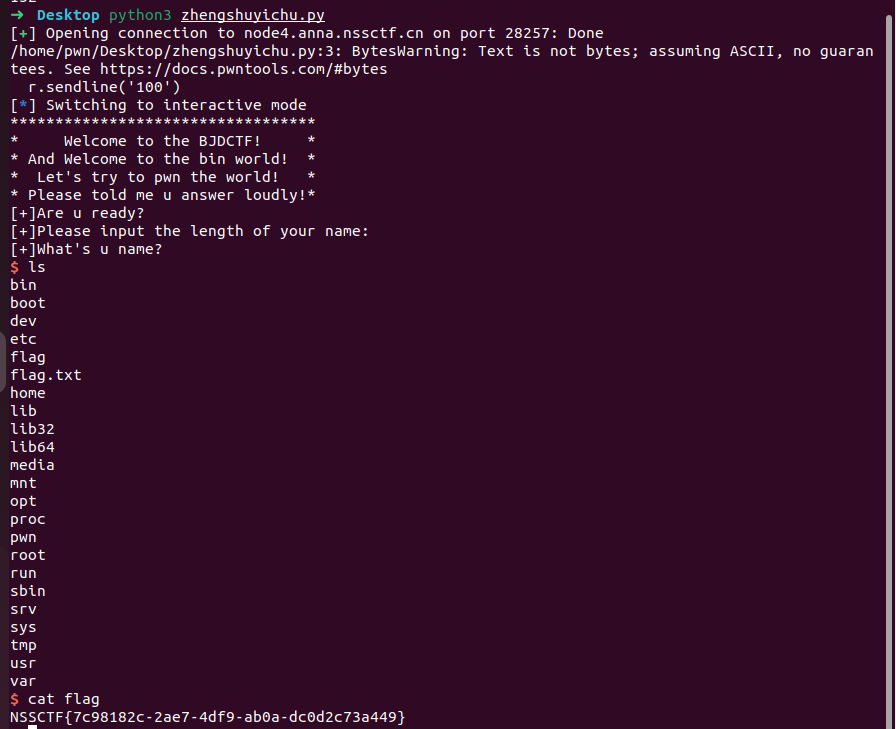
2)[BJDCTF 2020]babystack2.0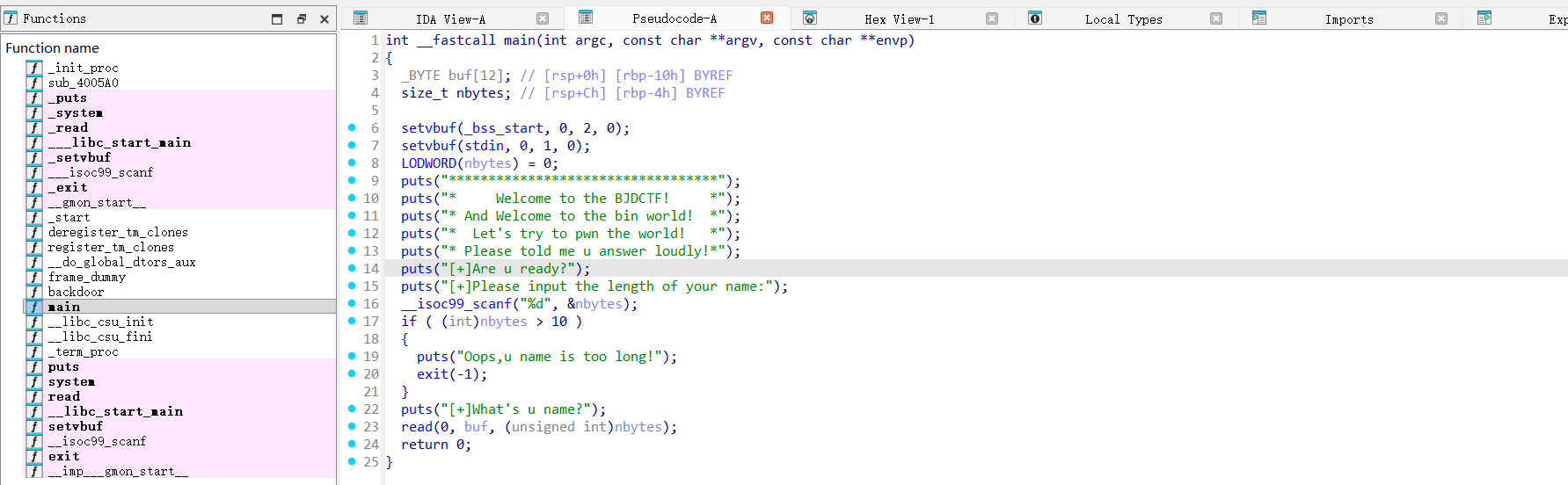
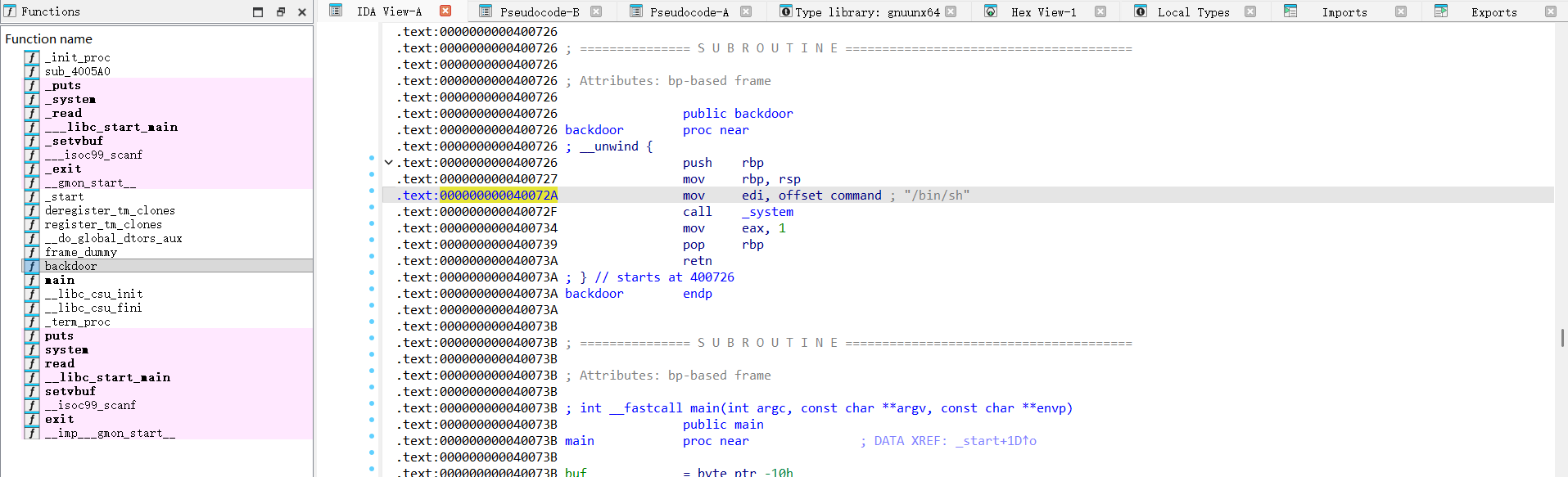
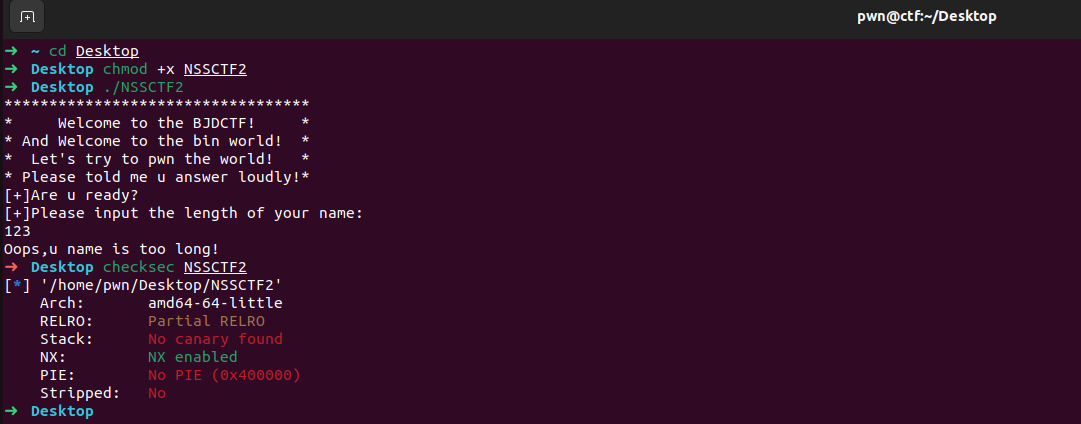
不同与上一题,限制了名字长度防止了由于长度不限制造成的栈溢出
如果想要让read函数存在溢出,起码要让read的nbytes大于0x10,但是又被上面的if条件给限制住了,不能大于0x10,那么这里存在一个整数溢出,如果我们输入的是 -1 那么就可以绕过if条件了,同时可以看到read函数的nbytes是unsigned int,unsigned int是无符号整型,遇到-1就会变成unsigned int的最大值,这样就可以让栈溢出
exp 2)
1 | from pwn import * |

更新: 2026-04-05 14:00:00
原文: https://www.yuque.com/idcm/wnemg9/zuig3xggn61of4bc