
House Of Rabbit
前言:查找其他题目 wp 的时候偶尔看见了这种利用手法,由于好奇就来了解一下,也算是扩展自己的攻击手法和视野,不过没有碰见合适的题目,以后遇见了在对例题进行补充。
在低版本 glibc ,House of Rabbit 是一种极具破坏力的堆利用手法。它的核心思想是利用 malloc_consolidate 机制的盲目性,将受到严格大小限制的 Fastbin 堆块,强行偷渡到审查宽松的 Unsorted Bin 中,从而实现任意地址分配或大规模堆重叠。
在 glibc 2.23 中,由于缺少了高版本中严苛的 system_mem 等检查,House of Rabbit 的威力可以发挥到极致
malloc_consolidate 漏洞:
Fastbin 以单链表形式存在,拥有非常严格的 size 检查。如果你想直接从 Fastbin 申请出你伪造的 chunk,你伪造的 size 必须与请求的大小精确匹配(fastbin_index 检查)。这在 BSS 段或栈上往往很难伪造。
malloc_consolidate:
当程序申请 Large Bin 级别的内存(通常 > 0x400),或者调用 free 导致 Unsorted Bin 里的 chunk 与 Top Chunk 合并时,glibc 就会触发 malloc_consolidate。
这个函数会遍历所有的 Fastbin,清除这些 chunk 的 PREV_INUSE 标志位,尝试将相邻的空闲堆块合并,并将它们放入 Unsorted Bin。
但是漏洞在于程序员开发 mallc_consolidate 函数的时候默认 fastbin_size 一定合法,因而 malloc_consolidate 遍历 Fastbin 时,完全没有检查 chunk 的 size 是否合法, 它只管顺着 fd 指针往下找。
1 | // malloc_consolidate |
house of rabbit 攻击流程(以 glibc 2.23 为例)
假设我们的目标是在某个地址,分配一块内存。比如 BSS 段上的某段地址,这里我们称之为 target_addr
在目标地址伪造 Chunk
在 target_addr 附近伪造一个 chunk 头部。由于最终我们要把它送进 Unsorted Bin,我们可以给它赋予一个极大的 Size,我们这里默认修改成 0x80000
- 为了防止 malloc_consolidate 在寻找 next_chunk 时发生段错误,target_addr + fake_size 所在的地址必须是可读写的内存区域。
劫持 Fastbin 链表
分配一个 Fastbin 大小的 Chunk A,然后将其释放。此时 Chunk A 进入 Fastbin。
利用 UAF 或溢出漏洞,将 Chunk A 的 fd 指针修改为指向我们伪造的 fake_chunk。
- 此时的单链表:
Fastbin Head -> Chunk A -> fake_chunk
触发 malloc_consolidate
控制程序 malloc 一个较大的内存。glibc 发现 Fastbin 里有碎片,触发 malloc_consolidate 进行整理。
- glibc 最开始检查 Chunk A,计算它的下一个 chunk,取消 INUSE 位,把 Chunk A 扔进 Unsorted Bin。
- 顺着 fd 指针,看到我们的 fake_chunk。
- 它不会检查 fake_chunk 为什么会在 Fastbin 里,也不会管它的 size 为什么是极大的 0x80000。
- 它直接根据 0x80000 找到下一个伪造的 chunk,清除那个位置的 INUSE 位。
- 之后就直接将 fake_chunk 投入 Unsorted Bin 当中了
从 Unsorted Bin 中切割劫持 chunk
此时,Unsorted Bin 中躺着一个位于 target_addr、大小为 0x80000 的巨大堆块。
你只需要再次调用 malloc 申请你实际需要的内存大小,glibc 就会从这个巨大的 fake_chunk 中切割一块给你。
由于我们伪造的是 bss 段上的地址,我们就可以随意对其内容进行篡改从而获取 shell
看两个例子:我们分别称之为 demo1 和 demo2:
demo1 modify the size of fastbin chunk:
1 |
|
最开始两次 malloc 之后:

chunk1[-1]=0xa1 之后对 chunk1 的 size 进行了修改让其数值变大,之后申请大堆块触发 malloc_consolidate
malloc(0x400)之后:
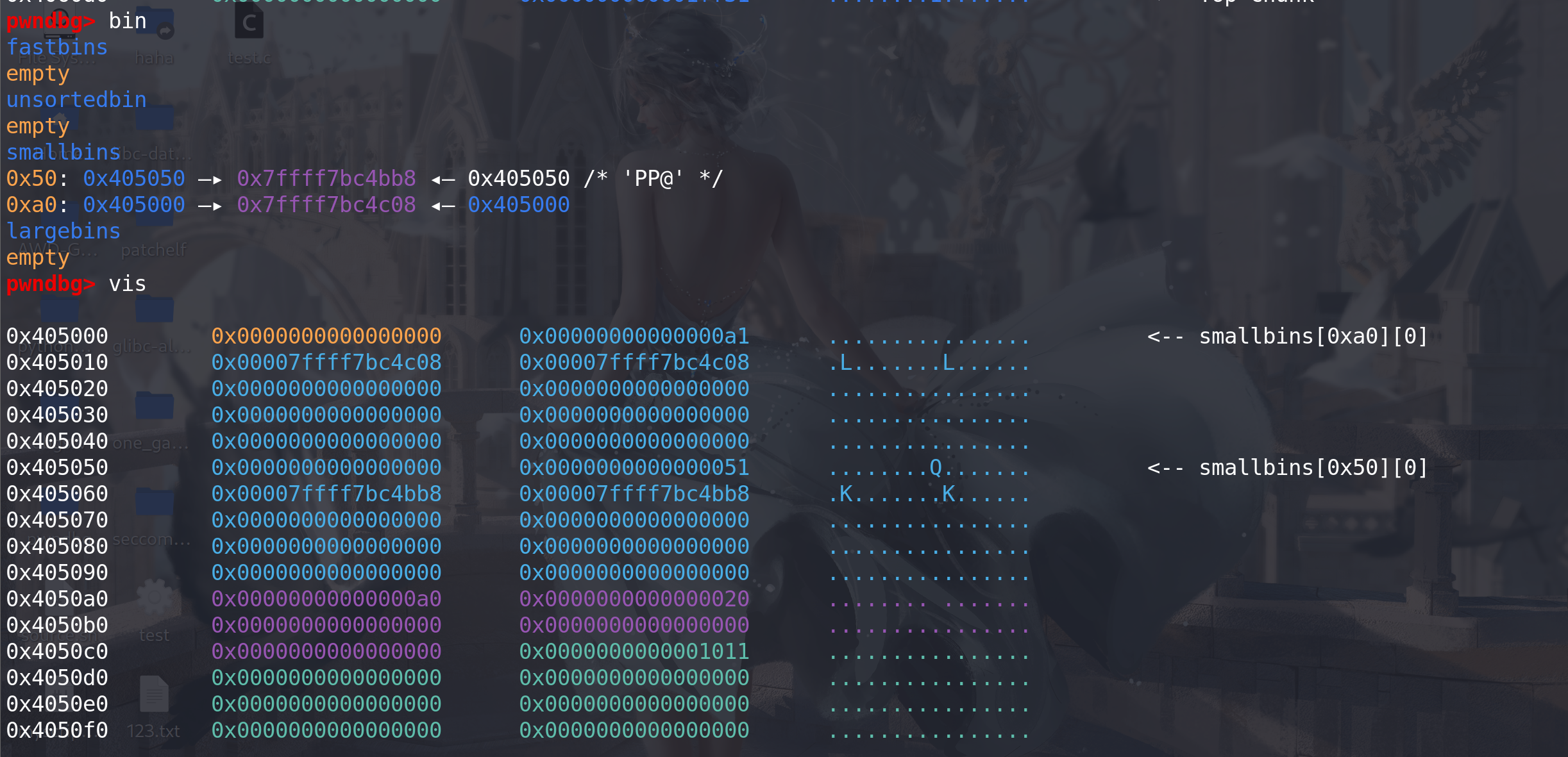
可以发现此时两个 fastbin 已经全部进入到了 Smallbin 当中,并且成功制造出来了一个堆重叠
demo2 modify FD pointer:
1 |
|
- 在
glibc 2.31及更高的版本中,House of Rabbit 已经从“一击必杀”的终极武器,退化成了利用链条中的一环。它的核心使命变成了:在堆空间内部制造合法的“堆块重叠(Heap Overlapping)”,为后续的 Tcache Poisoning(Tcache 投毒)铺路。
在现代 Pwn 题中,一般会按照以下标准套路来使用它。我们可以把这个过程想象成“吃掉邻居的地盘”。
💥 核心思路:通过 Rabbit 制造重叠,通过 Tcache 拿 Shell
为了让你更直观地理解,我们假设堆上有三个相邻的正常 Chunk:
- Chunk A (准备丢入 Fastbin 的诱饵)
- Chunk B (受害者,准备被覆盖)
- Chunk C (防线,用来伪造 Next Chunk 绕过检查)
🐾 Step-by-Step 现代利用流程
1. 内存布局与伪造 Next Chunk (最关键的难点)
在 2.31 中,由于有 next_chunk->size 的检查,你不能随便写个 Fake Size 就跑。你必须保证 Chunk A + Fake_Size 指向的位置,存在一个合法的 Chunk 头。
- 操作: 我们预先计算好,打算让 Chunk A 的大小“膨胀”并刚好包裹住 Chunk B。那么
Fake_Size = 正常A的大小 + B的大小。 - 布置: 我们利用正常的分配,在
Chunk A + Fake_Size的位置布置好 Chunk C。确保 Chunk C 的size字段是合法的,并且它的PREV_INUSE标志位为 1。
2. 填满 Tcache
这是 2.31 绕不开的坎。因为 Chunk A 的大小(未膨胀前)一般较小,如果你直接 free,它会优先进入 Tcache。
- 操作: 连续
free7 个与 Chunk A 同样大小的堆块,把对应大小的 Tcache 垃圾桶塞满。
3. 释放目标进入 Fastbin
- 操作: 释放
Chunk A。因为 Tcache 已经满了,Chunk A只能委屈地进入 Fastbin。
4. UAF / 越界写:修改 Size
- 操作: 触发你程序里的漏洞(比如 Use-After-Free 或者堆溢出),去修改躺在 Fastbin 里的
Chunk A的size字段。 - 将其修改为前面计算好的
Fake_Size。 - 注意: 这个
Fake_Size必须小于av->system_mem(通常在 132KB 左右),这就是为什么现在只能在堆内重叠,不能跨越到 BSS 段的原因。
5. 触发 malloc_consolidate (见证奇迹的时刻)
- 操作: 申请一个大于 Large Bin 范围的堆块(比如申请
0x400以上的大小)。 - 内部发生的事:
glibc开始整理碎片,遍历 Fastbin 发现了Chunk A。它读取Chunk A巨大的Fake_Size,然后向后找Next Chunk(此时完美匹配到了我们预先布置好的 Chunk C,绕过检查!)。 - 结果: 带着巨大 Size 的
Chunk A被合法地送进了 Unsorted Bin。此时,它在物理和逻辑上已经完全包裹(覆盖)了 Chunk B。
6. Tcache 投毒 (收割成果)
这个时候,情况变成了:Unsorted Bin 里的 Chunk A 和正常使用或被释放的 Chunk B重叠了。
- 我们将
Chunk B释放进 Tcache。 - 我们从 Unsorted Bin 再次
malloc申请内存(从膨胀的Chunk A里切出一块,大小正好覆盖到Chunk B)。 - 因为我们拿到了这块内存的写权限,我们可以直接篡改下方
Chunk B的fd指针,将其指向任意目标地址(比如__free_hook或者栈上的返回地址)。 - 最后,连续两次
malloc同等大小的 Tcache,第二次就会把目标地址分配给你,实现任意地址写!
💡 总结
2.31 之后,House of Rabbit 的通常用法是:“伪造 Size -> Consolidate 制造堆重叠 -> 篡改重叠块的 fd 劫持 Tcache -> 任意地址写”。它变成了一个精密的“接力赛”第一棒。
这个过程涉及的内存布局比较讲究,你是否需要我用简单的文本图解(ASCII 图)画一下 Chunk A, B, C 在内存中被包裹和重叠的具体状态?在 glibc 2.31 及更高的版本中,House of Rabbit 已经从“一击必杀”的终极武器,退化成了利用链条中的一环。它的核心使命变成了:在堆空间内部制造合法的“堆块重叠(Heap Overlapping)”,为后续的 Tcache Poisoning(Tcache 投毒)铺路。
在现代 Pwn 题中,一般会按照以下标准套路来使用它。我们可以把这个过程想象成“吃掉邻居的地盘”。
💥 核心思路:通过 Rabbit 制造重叠,通过 Tcache 拿 Shell
为了让你更直观地理解,我们假设堆上有三个相邻的正常 Chunk:
- Chunk A (准备丢入 Fastbin 的诱饵)
- Chunk B (受害者,准备被覆盖)
- Chunk C (防线,用来伪造 Next Chunk 绕过检查)
🐾 Step-by-Step 现代利用流程
1. 内存布局与伪造 Next Chunk (最关键的难点)
在 2.31 中,由于有 next_chunk->size 的检查,你不能随便写个 Fake Size 就跑。你必须保证 Chunk A + Fake_Size 指向的位置,存在一个合法的 Chunk 头。
- 操作: 我们预先计算好,打算让 Chunk A 的大小“膨胀”并刚好包裹住 Chunk B。那么
Fake_Size = 正常A的大小 + B的大小。 - 布置: 我们利用正常的分配,在
Chunk A + Fake_Size的位置布置好 Chunk C。确保 Chunk C 的size字段是合法的,并且它的PREV_INUSE标志位为 1。
2. 填满 Tcache
这是 2.31 绕不开的坎。因为 Chunk A 的大小(未膨胀前)一般较小,如果你直接 free,它会优先进入 Tcache。
- 操作: 连续
free7 个与 Chunk A 同样大小的堆块,把对应大小的 Tcache 垃圾桶塞满。
3. 释放目标进入 Fastbin
- 操作: 释放
Chunk A。因为 Tcache 已经满了,Chunk A只能委屈地进入 Fastbin。
4. UAF / 越界写:修改 Size
- 操作: 触发你程序里的漏洞(比如 Use-After-Free 或者堆溢出),去修改躺在 Fastbin 里的
Chunk A的size字段。 - 将其修改为前面计算好的
Fake_Size。 - 注意: 这个
Fake_Size必须小于av->system_mem(通常在 132KB 左右),这就是为什么现在只能在堆内重叠,不能跨越到 BSS 段的原因。
5. 触发 malloc_consolidate (见证奇迹的时刻)
- 操作: 申请一个大于 Large Bin 范围的堆块(比如申请
0x400以上的大小)。 - 内部发生的事:
glibc开始整理碎片,遍历 Fastbin 发现了Chunk A。它读取Chunk A巨大的Fake_Size,然后向后找Next Chunk(此时完美匹配到了我们预先布置好的 Chunk C,绕过检查!)。 - 结果: 带着巨大 Size 的
Chunk A被合法地送进了 Unsorted Bin。此时,它在物理和逻辑上已经完全包裹(覆盖)了 Chunk B。
6. Tcache 投毒 (收割成果)
这个时候,情况变成了:Unsorted Bin 里的 Chunk A 和正常使用或被释放的 Chunk B重叠了。
- 我们将
Chunk B释放进 Tcache。 - 我们从 Unsorted Bin 再次
malloc申请内存(从膨胀的Chunk A里切出一块,大小正好覆盖到Chunk B)。 - 因为我们拿到了这块内存的写权限,我们可以直接篡改下方
Chunk B的fd指针,将其指向任意目标地址(比如__free_hook或者栈上的返回地址)。 - 最后,连续两次
malloc同等大小的 Tcache,第二次就会把目标地址分配给你,实现任意地址写!
💡 总结
2.31 之后,House of Rabbit 的通常用法是:“伪造 Size -> Consolidate 制造堆重叠 -> 篡改重叠块的 fd 劫持 Tcache -> 任意地址写”。它变成了一个精密的“接力赛”第一棒。
这个过程涉及的内存布局比较讲究,你是否需要我用简单的文本图解(ASCII 图)画一下 Chunk A, B, C 在内存中被包裹和重叠的具体状态?在 glibc 2.31 及更高的版本中,House of Rabbit 已经从“一击必杀”的终极武器,退化成了利用链条中的一环。它的核心使命变成了:在堆空间内部制造合法的“堆块重叠(Heap Overlapping)”,为后续的 Tcache Poisoning(Tcache 投毒)铺路。
在现代 Pwn 题中,一般会按照以下标准套路来使用它。我们可以把这个过程想象成“吃掉邻居的地盘”。
💥 核心思路:通过 Rabbit 制造重叠,通过 Tcache 拿 Shell
为了让你更直观地理解,我们假设堆上有三个相邻的正常 Chunk:
- Chunk A (准备丢入 Fastbin 的诱饵)
- Chunk B (受害者,准备被覆盖)
- Chunk C (防线,用来伪造 Next Chunk 绕过检查)
🐾 Step-by-Step 现代利用流程
1. 内存布局与伪造 Next Chunk (最关键的难点)
在 2.31 中,由于有 next_chunk->size 的检查,你不能随便写个 Fake Size 就跑。你必须保证 Chunk A + Fake_Size 指向的位置,存在一个合法的 Chunk 头。
- 操作: 我们预先计算好,打算让 Chunk A 的大小“膨胀”并刚好包裹住 Chunk B。那么
Fake_Size = 正常A的大小 + B的大小。 - 布置: 我们利用正常的分配,在
Chunk A + Fake_Size的位置布置好 Chunk C。确保 Chunk C 的size字段是合法的,并且它的PREV_INUSE标志位为 1。
2. 填满 Tcache
这是 2.31 绕不开的坎。因为 Chunk A 的大小(未膨胀前)一般较小,如果你直接 free,它会优先进入 Tcache。
- 操作: 连续
free7 个与 Chunk A 同样大小的堆块,把对应大小的 Tcache 垃圾桶塞满。
3. 释放目标进入 Fastbin
- 操作: 释放
Chunk A。因为 Tcache 已经满了,Chunk A只能委屈地进入 Fastbin。
4. UAF / 越界写:修改 Size
- 操作: 触发你程序里的漏洞(比如 Use-After-Free 或者堆溢出),去修改躺在 Fastbin 里的
Chunk A的size字段。 - 将其修改为前面计算好的
Fake_Size。 - 注意: 这个
Fake_Size必须小于av->system_mem(通常在 132KB 左右),这就是为什么现在只能在堆内重叠,不能跨越到 BSS 段的原因。
5. 触发 malloc_consolidate (见证奇迹的时刻)
- 操作: 申请一个大于 Large Bin 范围的堆块(比如申请
0x400以上的大小)。 - 内部发生的事:
glibc开始整理碎片,遍历 Fastbin 发现了Chunk A。它读取Chunk A巨大的Fake_Size,然后向后找Next Chunk(此时完美匹配到了我们预先布置好的 Chunk C,绕过检查!)。 - 结果: 带着巨大 Size 的
Chunk A被合法地送进了 Unsorted Bin。此时,它在物理和逻辑上已经完全包裹(覆盖)了 Chunk B。
6. Tcache 投毒 (收割成果)
这个时候,情况变成了:Unsorted Bin 里的 Chunk A 和正常使用或被释放的 Chunk B重叠了。
- 我们将
Chunk B释放进 Tcache。 - 我们从 Unsorted Bin 再次
malloc申请内存(从膨胀的Chunk A里切出一块,大小正好覆盖到Chunk B)。 - 因为我们拿到了这块内存的写权限,我们可以直接篡改下方
Chunk B的fd指针,将其指向任意目标地址(比如__free_hook或者栈上的返回地址)。 - 最后,连续两次
malloc同等大小的 Tcache,第二次就会把目标地址分配给你,实现任意地址写!
💡 总结
2.31 之后,House of Rabbit 的通常用法是:“伪造 Size -> Consolidate 制造堆重叠 -> 篡改重叠块的 fd 劫持 Tcache -> 任意地址写”。它变成了一个精密的“接力赛”第一棒。
这个过程涉及的内存布局比较讲究,你是否需要我用简单的文本图解(ASCII 图)画一下 Chunk A, B, C 在内存中被包裹和重叠的具体状态?在 glibc 2.31 及更高的版本中,House of Rabbit 已经从“一击必杀”的终极武器,退化成了利用链条中的一环。它的核心使命变成了:在堆空间内部制造合法的“堆块重叠(Heap Overlapping)”,为后续的 Tcache Poisoning(Tcache 投毒)铺路。
在现代 Pwn 题中,一般会按照以下标准套路来使用它。我们可以把这个过程想象成“吃掉邻居的地盘”。
💥 核心思路:通过 Rabbit 制造重叠,通过 Tcache 拿 Shell
为了让你更直观地理解,我们假设堆上有三个相邻的正常 Chunk:
- Chunk A (准备丢入 Fastbin 的诱饵)
- Chunk B (受害者,准备被覆盖)
- Chunk C (防线,用来伪造 Next Chunk 绕过检查)
🐾 Step-by-Step 现代利用流程
1. 内存布局与伪造 Next Chunk (最关键的难点)
在 2.31 中,由于有 next_chunk->size 的检查,你不能随便写个 Fake Size 就跑。你必须保证 Chunk A + Fake_Size 指向的位置,存在一个合法的 Chunk 头。
- 操作: 我们预先计算好,打算让 Chunk A 的大小“膨胀”并刚好包裹住 Chunk B。那么
Fake_Size = 正常A的大小 + B的大小。 - 布置: 我们利用正常的分配,在
Chunk A + Fake_Size的位置布置好 Chunk C。确保 Chunk C 的size字段是合法的,并且它的PREV_INUSE标志位为 1。
2. 填满 Tcache
这是 2.31 绕不开的坎。因为 Chunk A 的大小(未膨胀前)一般较小,如果你直接 free,它会优先进入 Tcache。
- 操作: 连续
free7 个与 Chunk A 同样大小的堆块,把对应大小的 Tcache 垃圾桶塞满。
3. 释放目标进入 Fastbin
- 操作: 释放
Chunk A。因为 Tcache 已经满了,Chunk A只能委屈地进入 Fastbin。
4. UAF / 越界写:修改 Size
- 操作: 触发你程序里的漏洞(比如 Use-After-Free 或者堆溢出),去修改躺在 Fastbin 里的
Chunk A的size字段。 - 将其修改为前面计算好的
Fake_Size。 - 注意: 这个
Fake_Size必须小于av->system_mem(通常在 132KB 左右),这就是为什么现在只能在堆内重叠,不能跨越到 BSS 段的原因。
5. 触发 malloc_consolidate (见证奇迹的时刻)
- 操作: 申请一个大于 Large Bin 范围的堆块(比如申请
0x400以上的大小)。 - 内部发生的事:
glibc开始整理碎片,遍历 Fastbin 发现了Chunk A。它读取Chunk A巨大的Fake_Size,然后向后找Next Chunk(此时完美匹配到了我们预先布置好的 Chunk C,绕过检查!)。 - 结果: 带着巨大 Size 的
Chunk A被合法地送进了 Unsorted Bin。此时,它在物理和逻辑上已经完全包裹(覆盖)了 Chunk B。
6. Tcache 投毒 (收割成果)
这个时候,情况变成了:Unsorted Bin 里的 Chunk A 和正常使用或被释放的 Chunk B重叠了。
- 我们将
Chunk B释放进 Tcache。 - 我们从 Unsorted Bin 再次
malloc申请内存(从膨胀的Chunk A里切出一块,大小正好覆盖到Chunk B)。 - 因为我们拿到了这块内存的写权限,我们可以直接篡改下方
Chunk B的fd指针,将其指向任意目标地址(比如__free_hook或者栈上的返回地址)。 - 最后,连续两次
malloc同等大小的 Tcache,第二次就会把目标地址分配给你,实现任意地址写!
💡 总结
2.31 之后,House of Rabbit 的通常用法是:“伪造 Size -> Consolidate 制造堆重叠 -> 篡改重叠块的 fd 劫持 Tcache -> 任意地址写”。它变成了一个精密的“接力赛”第一棒。
这个过程涉及的内存布局比较讲究,你是否需要我用简单的文本图解(ASCII 图)画一下 Chunk A, B, C 在内存中被包裹和重叠的具体状态?
6. Tcache 投毒
这个时候,情况变成了:Unsorted Bin 里的 Chunk A 和正常使用或被释放的 Chunk B重叠了。
- 我们将
Chunk B释放进 Tcache。 - 我们从 Unsorted Bin 再次
malloc申请内存(从膨胀的Chunk A里切出一块,大小正好覆盖到Chunk B)。 - 因为我们拿到了这块内存的写权限,我们可以直接篡改下方
Chunk B的fd指针,将其指向任意目标地址(比如__free_hook或者栈上的返回地址)。 - 最后,连续两次
malloc同等大小的 Tcache,第二次就会把目标地址分配给你,实现任意地址写!
💡 总结
2.31 之后,House of Rabbit 的通常用法是:“伪造 Size -> Consolidate 制造堆重叠 -> 篡改重叠块的 fd 劫持 Tcache -> 任意地址写”。它变成了一个精密的“接力赛”第一棒。
这个过程涉及的内存布局比较讲究,你是否需要我用简单的文本图解(ASCII 图)画一下 Chunk A, B, C 在内存中被包裹和重叠的具体状态?
更新: 2026-05-03 00:36:18
原文: https://www.yuque.com/idcm/wnemg9/tlohtg5p20y48e96
